‘hidden-information game’ directory
- See Also
- Links
- “BetaZero: Belief-State Planning for Long-Horizon POMDPs Using Learned Approximations ”, Moss et al 2023
- “Posterior Sampling for Multi-Agent Reinforcement Learning: Solving Extensive Games With Imperfect Information ”, Zhou et al 2023
- “AlphaZe∗∗: AlphaZero-Like Baselines for Imperfect Information Games Are Surprisingly Strong ”, Blüml et al 2023
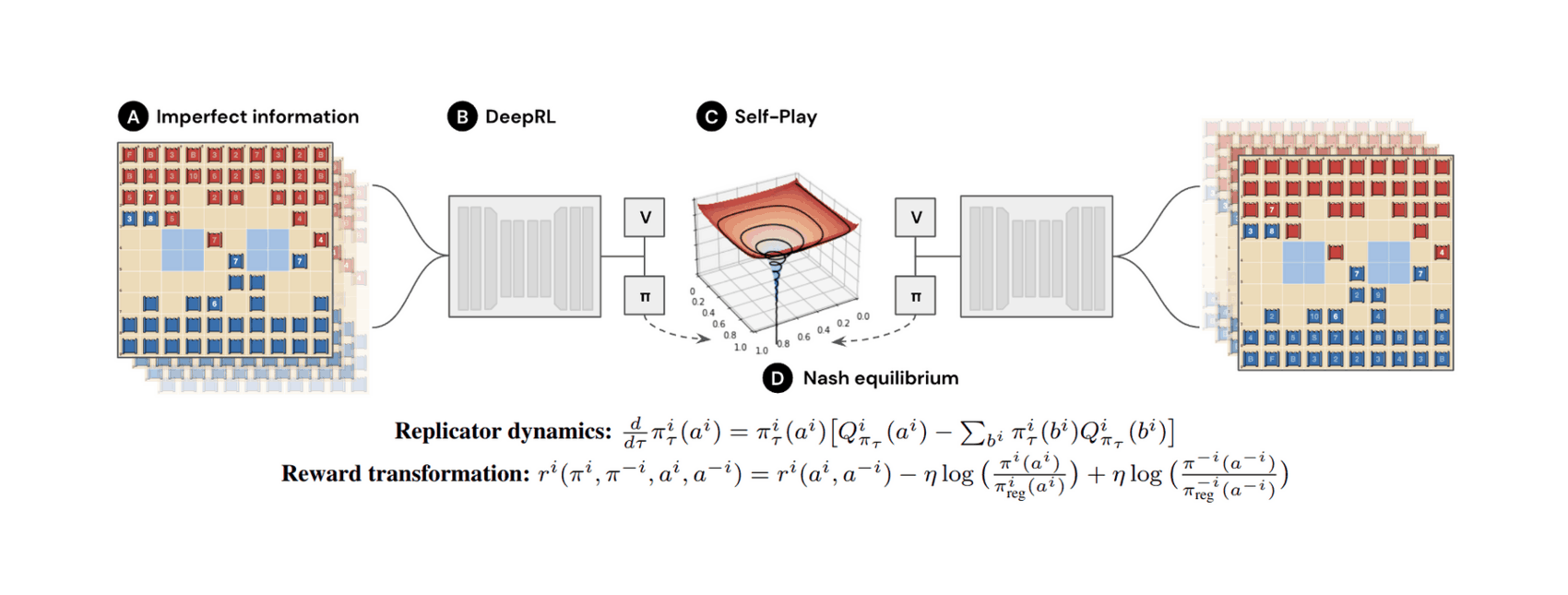
- “DeepNash: Mastering the Game of Stratego With Model-Free Multiagent Reinforcement Learning ”, Perolat et al 2022
- “DouZero: Mastering DouDizhu With Self-Play Deep Reinforcement Learning ”, Zha et al 2021
- “Vector Quantized Models for Planning ”, Ozair et al 2021
- “Suphx: Mastering Mahjong With Deep Reinforcement Learning ”, Li et al 2020
- “From Poincaré Recurrence to Convergence in Imperfect Information Games: Finding Equilibrium via Regularization ”, Perolat et al 2020
- “Finding Friend and Foe in Multi-Agent Games ”, Serrino et al 2019
- “Monte Carlo Neural Fictitious Self-Play: Approach to Approximate Nash Equilibrium of Imperfect-Information Games ”, Zhang et al 2019
- “A Survey and Critique of Multiagent Deep Reinforcement Learning ”, Hernandez-Leal et al 2018
- “Solving Imperfect-Information Games via Discounted Regret Minimization ”, Brown & Sandholm 2018
- “ExIt-OOS: Towards Learning from Planning in Imperfect Information Games ”, Kitchen & Benedetti 2018
- “Regret Minimization for Partially Observable Deep Reinforcement Learning ”, Jin et al 2017
- “LADDER: A Human-Level Bidding Agent for Large-Scale Real-Time Online Auctions ”, Wang et al 2017
- “Deep Recurrent Q-Learning for Partially Observable MDPs ”, Hausknecht & Stone 2015
- “Monte-Carlo Planning in Large POMDPs ”, Silver & Veness 2010
- “One Writer Enters International Competition to Play the World-Conquering Game That Redefines What It Means to Be a Geek (And a Person) ”
- “So Has AI Conquered Bridge? ”
- “The Steely, Headless King of Texas Hold’Em ”
- “Artificial Intelligence Beats Eight World Champions at Bridge ”
- “A Poker-Playing Robot Goes to Work for the Pentagon ”
- Wikipedia (1)
- Miscellaneous
- Bibliography
See Also
Links
“BetaZero: Belief-State Planning for Long-Horizon POMDPs Using Learned Approximations ”, Moss et al 2023
BetaZero: Belief-State Planning for Long-Horizon POMDPs using Learned Approximations
“Posterior Sampling for Multi-Agent Reinforcement Learning: Solving Extensive Games With Imperfect Information ”, Zhou et al 2023
“AlphaZe∗∗: AlphaZero-Like Baselines for Imperfect Information Games Are Surprisingly Strong ”, Blüml et al 2023
AlphaZe∗∗: AlphaZero-like baselines for imperfect information games are surprisingly strong
“DeepNash: Mastering the Game of Stratego With Model-Free Multiagent Reinforcement Learning ”, Perolat et al 2022
DeepNash: Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
“DouZero: Mastering DouDizhu With Self-Play Deep Reinforcement Learning ”, Zha et al 2021
DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
“Vector Quantized Models for Planning ”, Ozair et al 2021
“Suphx: Mastering Mahjong With Deep Reinforcement Learning ”, Li et al 2020
“From Poincaré Recurrence to Convergence in Imperfect Information Games: Finding Equilibrium via Regularization ”, Perolat et al 2020
“Finding Friend and Foe in Multi-Agent Games ”, Serrino et al 2019
“Monte Carlo Neural Fictitious Self-Play: Approach to Approximate Nash Equilibrium of Imperfect-Information Games ”, Zhang et al 2019
“A Survey and Critique of Multiagent Deep Reinforcement Learning ”, Hernandez-Leal et al 2018
A Survey and Critique of Multiagent Deep Reinforcement Learning
“Solving Imperfect-Information Games via Discounted Regret Minimization ”, Brown & Sandholm 2018
Solving Imperfect-Information Games via Discounted Regret Minimization
“ExIt-OOS: Towards Learning from Planning in Imperfect Information Games ”, Kitchen & Benedetti 2018
ExIt-OOS: Towards Learning from Planning in Imperfect Information Games
“Regret Minimization for Partially Observable Deep Reinforcement Learning ”, Jin et al 2017
Regret Minimization for Partially Observable Deep Reinforcement Learning
“LADDER: A Human-Level Bidding Agent for Large-Scale Real-Time Online Auctions ”, Wang et al 2017
LADDER: A Human-Level Bidding Agent for Large-Scale Real-Time Online Auctions
“Deep Recurrent Q-Learning for Partially Observable MDPs ”, Hausknecht & Stone 2015
“Monte-Carlo Planning in Large POMDPs ”, Silver & Veness 2010
“One Writer Enters International Competition to Play the World-Conquering Game That Redefines What It Means to Be a Geek (And a Person) ”
“So Has AI Conquered Bridge? ”
View External Link:
https://www.lesswrong.com/posts/yHxmJch8dJoH6dwwz/so-has-ai-conquered-bridge
“The Steely, Headless King of Texas Hold’Em ”
“Artificial Intelligence Beats Eight World Champions at Bridge ”
Artificial intelligence beats eight world champions at bridge
“A Poker-Playing Robot Goes to Work for the Pentagon ”
A Poker-Playing Robot Goes to Work for the Pentagon :
View External Link:
https://www.wired.com/story/poker-playing-robot-goes-to-pentagon/
Wikipedia (1)
Miscellaneous
{kind=link}
Bibliography
https://arxiv.org/abs/2206.15378#deepmind: “DeepNash: Mastering the Game of Stratego With Model-Free Multiagent Reinforcement Learning ”,https://arxiv.org/abs/2106.04615#deepmind: “Vector Quantized Models for Planning ”,2010-silver.pdf: “Monte-Carlo Planning in Large POMDPs ”,