‘Decision Transformer’ directory
- See Also
- Links
- “Diffusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion ”, Chen et al 2024
- “Emergent World Models and Latent Variable Estimation in Chess-Playing Language Models ”, Karvonen 2024
- “A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task ”, Brinkmann et al 2024
- “Robust Agents Learn Causal World Models ”, Richens & Everitt 2024
- “Diff History for Neural Language Agents ”, Piterbarg et al 2023
- “Responsibility & Safety: Our Approach ”, DeepMind 2023
- “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb) ”, Zahavy et al 2023
- “PASTA: Pretrained Action-State Transformer Agents ”, Boige et al 2023
- “Supervised Pretraining Can Learn In-Context Reinforcement Learning ”, Lee et al 2023
- “Direct Preference Optimization (DPO): Your Language Model Is Secretly a Reward Model ”, Rafailov et al 2023
- “DPO § 6.4: Validating GPT-4 Judgments With Human Judgments ”, Rafailov et al 2023 (page 10)
- “Think Before You Act: Unified Policy for Interleaving Language Reasoning With Actions ”, Mezghani et al 2023
- “Learning Humanoid Locomotion With Transformers ”, Radosavovic et al 2023
- “Pretraining Language Models With Human Preferences ”, Korbak et al 2023
- “Conditioning Predictive Models: Risks and Strategies ”, Hubinger et al 2023
- “Language Models As Agent Models ”, Andreas 2022
- “In-Context Reinforcement Learning With Algorithm Distillation ”, Laskin et al 2022
- “Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task ”, Li et al 2022
- “
g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints ”, Peebles et al 2022 - “Trajectory Autoencoding Planner: Efficient Planning in a Compact Latent Action Space ”, Jiang et al 2022
- “Goal-Conditioned Generators of Deep Policies ”, Faccio et al 2022
- “Demis Hassabis: DeepMind—AI, Superintelligence & the Future of Humanity § Turing Test ”, Hassabis & Fridman 2022
- “Prompting Decision Transformer for Few-Shot Policy Generalization ”, Xu et al 2022
- “Boosting Search Engines With Interactive Agents ”, Ciaramita et al 2022
- “When Does Return-Conditioned Supervised Learning Work for Offline Reinforcement Learning? ”, Brandfonbrener et al 2022
- “You Can’t Count on Luck: Why Decision Transformers Fail in Stochastic Environments ”, Paster et al 2022
- “MAT: Multi-Agent Reinforcement Learning Is a Sequence Modeling Problem ”, Wen et al 2022
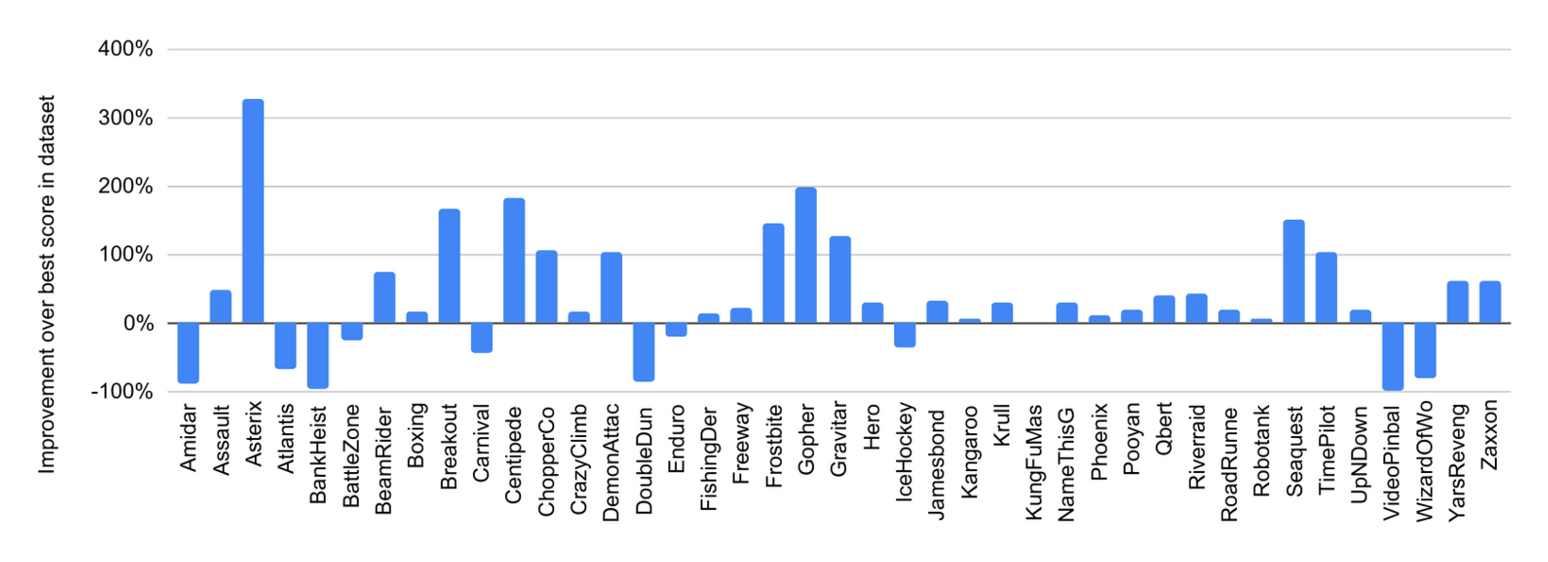
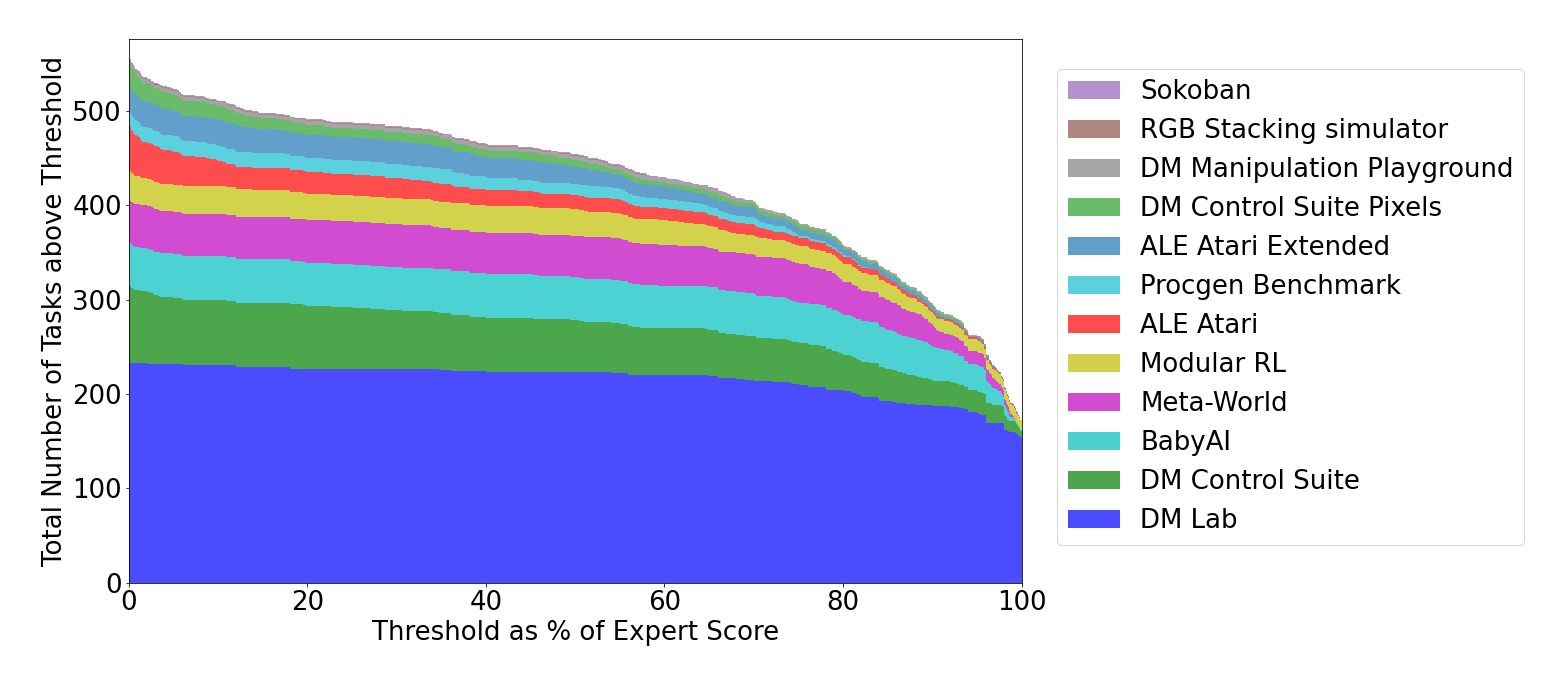
- “Multi-Game Decision Transformers ”, Lee et al 2022
- “Quark: Controllable Text Generation With Reinforced Unlearning ”, Lu et al 2022
- “Planning With Diffusion for Flexible Behavior Synthesis ”, Janner et al 2022
- “Gato: A Generalist Agent ”, Reed et al 2022
- “Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation? ”, Cui et al 2022
- “All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL ”, Arulkumaran et al 2022
- “Learning Relative Return Policies With Upside-Down Reinforcement Learning ”, Ashley et al 2022
- “NeuPL: Neural Population Learning ”, Liu et al 2022
- “ODT: Online Decision Transformer ”, Zheng et al 2022
- “Jury Learning: Integrating Dissenting Voices into Machine Learning Models ”, Gordon et al 2022
- “Can Wikipedia Help Offline Reinforcement Learning? ”, Reid et al 2022
- “In Defense of the Unitary Scalarization for Deep Multi-Task Learning ”, Kurin et al 2022
- “Offline Pre-Trained Multi-Agent Decision Transformer: One Big Sequence Model Tackles All SMAC Tasks ”, Meng et al 2021
- “Shaking the Foundations: Delusions in Sequence Models for Interaction and Control ”, Ortega et al 2021
- “Trajectory Transformer: Reinforcement Learning As One Big Sequence Modeling Problem ”, Janner et al 2021
- “Decision Transformer: Reinforcement Learning via Sequence Modeling ”, Chen et al 2021
- “Baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents ”, Alcorn & Nguyen 2021
- “The Go Transformer: Natural Language Modeling for Game Play ”, Ciolino et al 2020
- “Transformers Play Chess ”, Cheng 2020
- “A Very Unlikely Chess Game ”, Alexander 2020
- “Reinforcement Learning Upside Down: Don’t Predict Rewards—Just Map Them to Actions ”, Schmidhuber 2019
- “Training Agents Using Upside-Down Reinforcement Learning (UDRL) ”, Srivastava et al 2019
- “Reward Hacking Behavior Can Generalize across Tasks ”
- “Evidence of Learned Look-Ahead in a Chess-Playing Neural Network ”
- “Interview With Robert Kralisch on Simulators ”
- “TalkRL: The Reinforcement Learning Podcast: Aravind Srinivas 2: Aravind Srinivas, Research Scientist at OpenAI, Returns to Talk Decision Transformer, VideoGPT, Choosing Problems, and Explore vs Exploit in Research Careers ”
- “Supplementary Video for Do As I Can, Not As I Say: Grounding Language in Robotic Affordances ”
- Sort By Magic
- Miscellaneous
- Bibliography
See Also
Links
“Diffusion Forcing: Next-Token Prediction Meets Full-Sequence Diffusion ”, Chen et al 2024
Diffusion Forcing: Next-token Prediction Meets Full-Sequence Diffusion
“Emergent World Models and Latent Variable Estimation in Chess-Playing Language Models ”, Karvonen 2024
Emergent World Models and Latent Variable Estimation in Chess-Playing Language Models
“A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task ”, Brinkmann et al 2024
A Mechanistic Analysis of a Transformer Trained on a Symbolic Multi-Step Reasoning Task
“Robust Agents Learn Causal World Models ”, Richens & Everitt 2024
“Diff History for Neural Language Agents ”, Piterbarg et al 2023
“Responsibility & Safety: Our Approach ”, DeepMind 2023
“Diversifying AI: Towards Creative Chess With AlphaZero (AZdb) ”, Zahavy et al 2023
Diversifying AI: Towards Creative Chess with AlphaZero (AZdb)
“PASTA: Pretrained Action-State Transformer Agents ”, Boige et al 2023
“Supervised Pretraining Can Learn In-Context Reinforcement Learning ”, Lee et al 2023
Supervised Pretraining Can Learn In-Context Reinforcement Learning
“Direct Preference Optimization (DPO): Your Language Model Is Secretly a Reward Model ”, Rafailov et al 2023
Direct Preference Optimization (DPO): Your Language Model is Secretly a Reward Model
“DPO § 6.4: Validating GPT-4 Judgments With Human Judgments ”, Rafailov et al 2023 (page 10)
“Think Before You Act: Unified Policy for Interleaving Language Reasoning With Actions ”, Mezghani et al 2023
Think Before You Act: Unified Policy for Interleaving Language Reasoning with Actions
“Learning Humanoid Locomotion With Transformers ”, Radosavovic et al 2023
“Pretraining Language Models With Human Preferences ”, Korbak et al 2023
“Conditioning Predictive Models: Risks and Strategies ”, Hubinger et al 2023
“Language Models As Agent Models ”, Andreas 2022
“In-Context Reinforcement Learning With Algorithm Distillation ”, Laskin et al 2022
In-context Reinforcement Learning with Algorithm Distillation
“Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task ”, Li et al 2022
Emergent World Representations: Exploring a Sequence Model Trained on a Synthetic Task
“g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints ”, Peebles et al 2022
g.pt: Learning to Learn with Generative Models of Neural Network Checkpoints
“Trajectory Autoencoding Planner: Efficient Planning in a Compact Latent Action Space ”, Jiang et al 2022
Trajectory Autoencoding Planner: Efficient Planning in a Compact Latent Action Space
“Goal-Conditioned Generators of Deep Policies ”, Faccio et al 2022
“Demis Hassabis: DeepMind—AI, Superintelligence & the Future of Humanity § Turing Test ”, Hassabis & Fridman 2022
Demis Hassabis: DeepMind—AI, Superintelligence & the Future of Humanity § Turing Test
“Prompting Decision Transformer for Few-Shot Policy Generalization ”, Xu et al 2022
Prompting Decision Transformer for Few-Shot Policy Generalization
“Boosting Search Engines With Interactive Agents ”, Ciaramita et al 2022
“When Does Return-Conditioned Supervised Learning Work for Offline Reinforcement Learning? ”, Brandfonbrener et al 2022
When does return-conditioned supervised learning work for offline reinforcement learning?
“You Can’t Count on Luck: Why Decision Transformers Fail in Stochastic Environments ”, Paster et al 2022
You Can’t Count on Luck: Why Decision Transformers Fail in Stochastic Environments
“MAT: Multi-Agent Reinforcement Learning Is a Sequence Modeling Problem ”, Wen et al 2022
MAT: Multi-Agent Reinforcement Learning is a Sequence Modeling Problem
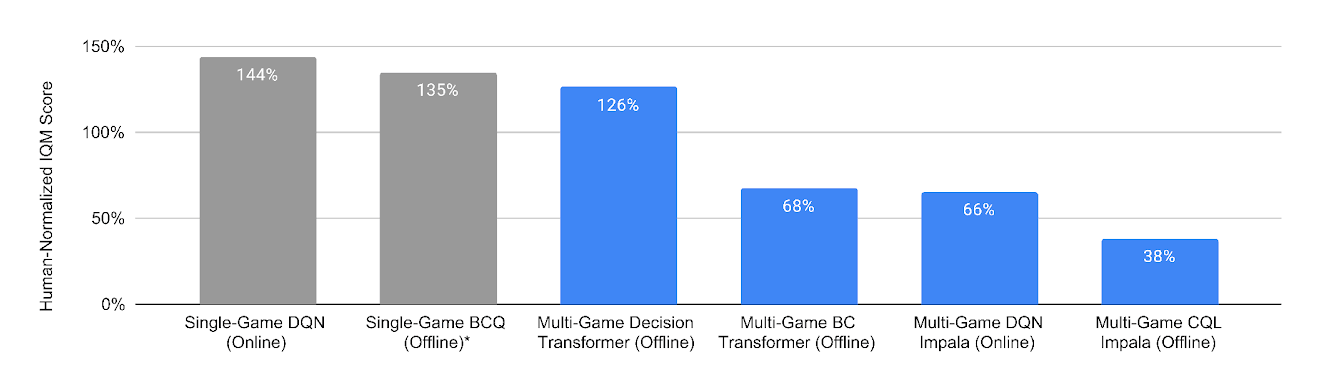
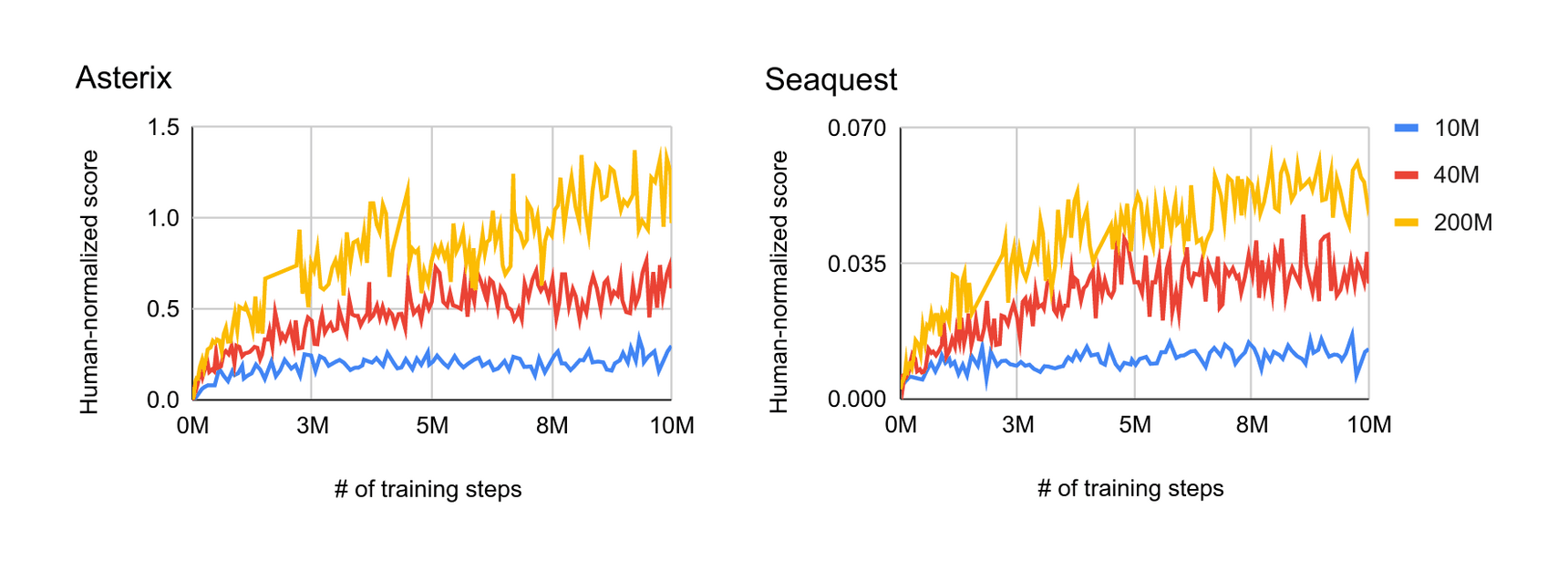
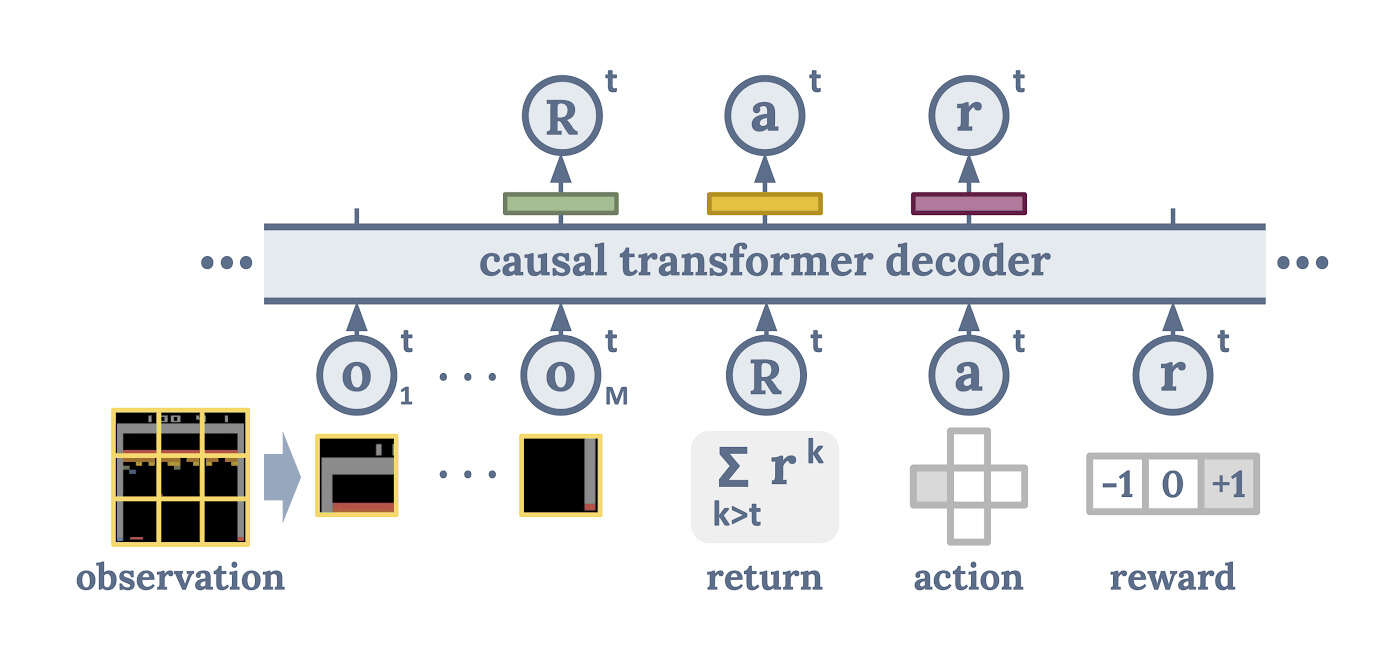
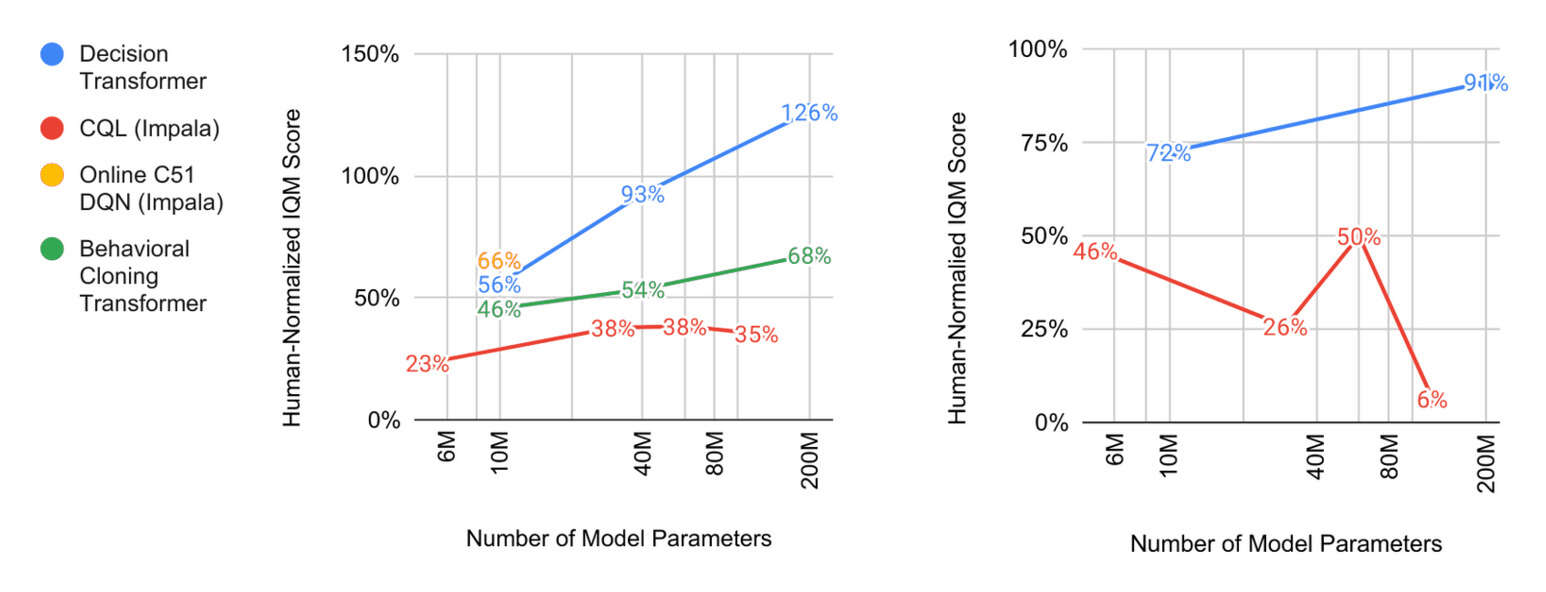
“Multi-Game Decision Transformers ”, Lee et al 2022
“Quark: Controllable Text Generation With Reinforced Unlearning ”, Lu et al 2022
Quark: Controllable Text Generation with Reinforced Unlearning
“Planning With Diffusion for Flexible Behavior Synthesis ”, Janner et al 2022
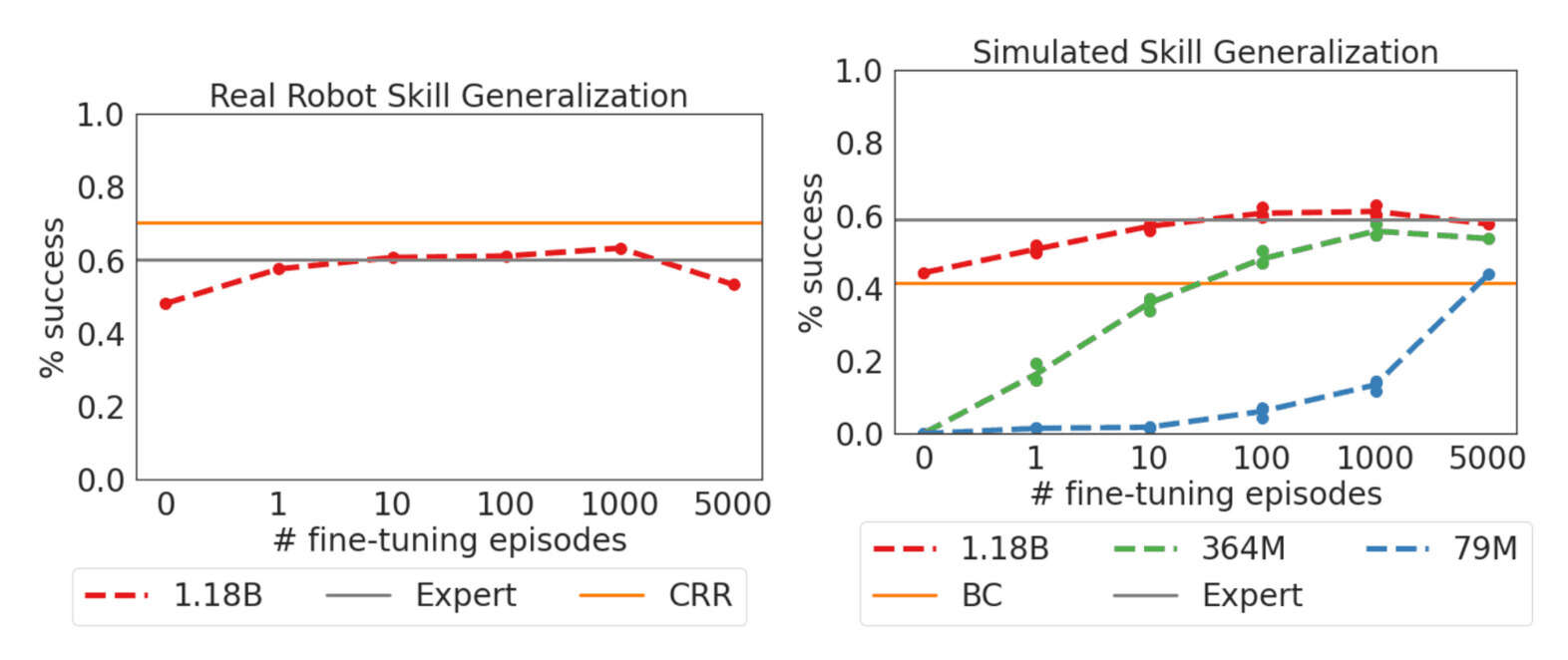
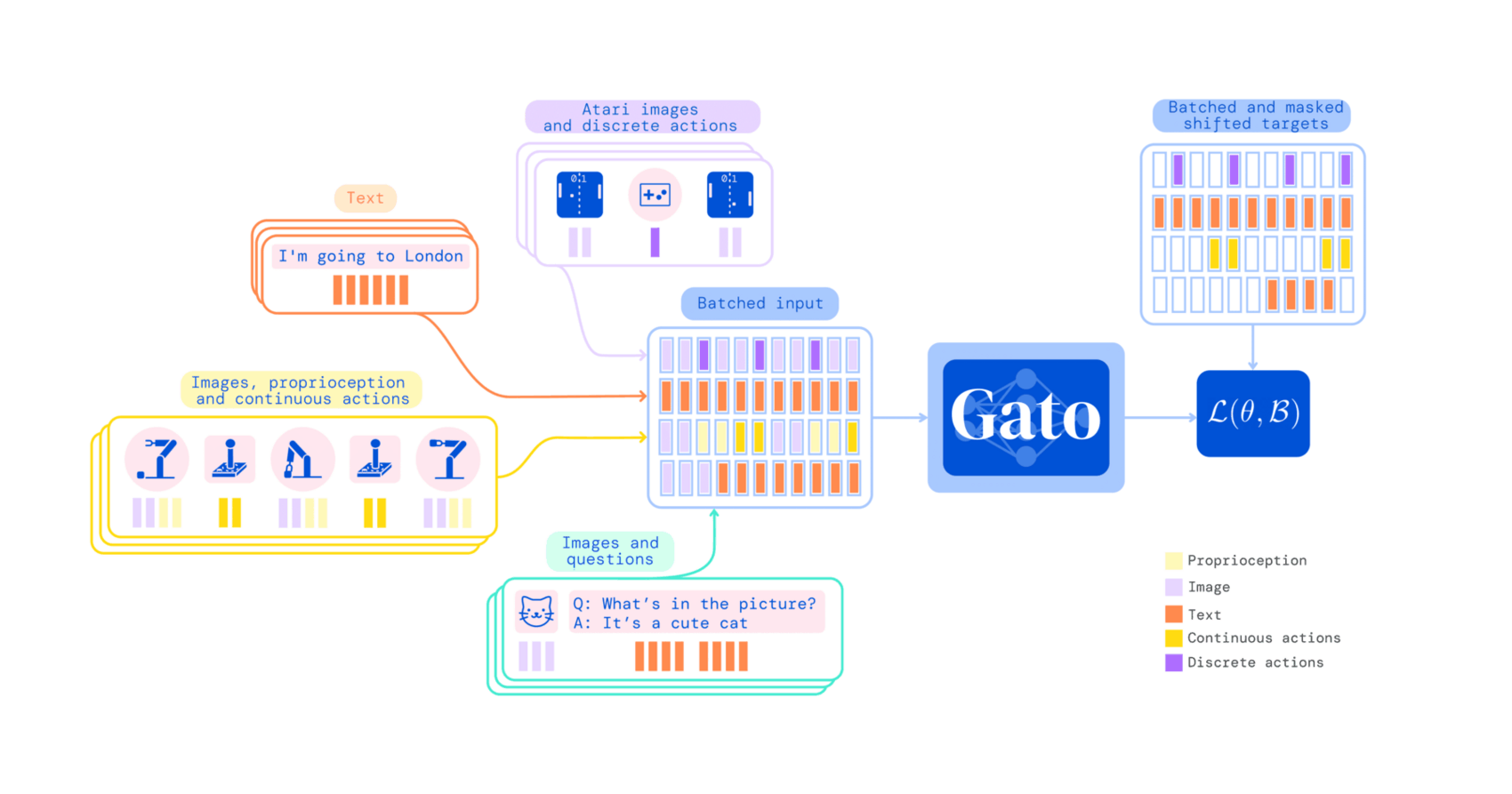
“Gato: A Generalist Agent ”, Reed et al 2022
“Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation? ”, Cui et al 2022
Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?
“All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL ”, Arulkumaran et al 2022
All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL
“Learning Relative Return Policies With Upside-Down Reinforcement Learning ”, Ashley et al 2022
Learning Relative Return Policies With Upside-Down Reinforcement Learning
“NeuPL: Neural Population Learning ”, Liu et al 2022
“ODT: Online Decision Transformer ”, Zheng et al 2022
“Jury Learning: Integrating Dissenting Voices into Machine Learning Models ”, Gordon et al 2022
Jury Learning: Integrating Dissenting Voices into Machine Learning Models
“Can Wikipedia Help Offline Reinforcement Learning? ”, Reid et al 2022
“In Defense of the Unitary Scalarization for Deep Multi-Task Learning ”, Kurin et al 2022
In Defense of the Unitary Scalarization for Deep Multi-Task Learning
“Offline Pre-Trained Multi-Agent Decision Transformer: One Big Sequence Model Tackles All SMAC Tasks ”, Meng et al 2021
Offline Pre-trained Multi-Agent Decision Transformer: One Big Sequence Model Tackles All SMAC Tasks
“Shaking the Foundations: Delusions in Sequence Models for Interaction and Control ”, Ortega et al 2021
Shaking the foundations: delusions in sequence models for interaction and control
“Trajectory Transformer: Reinforcement Learning As One Big Sequence Modeling Problem ”, Janner et al 2021
Trajectory Transformer: Reinforcement Learning as One Big Sequence Modeling Problem
“Decision Transformer: Reinforcement Learning via Sequence Modeling ”, Chen et al 2021
Decision Transformer: Reinforcement Learning via Sequence Modeling
“Baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents ”, Alcorn & Nguyen 2021
baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents
“The Go Transformer: Natural Language Modeling for Game Play ”, Ciolino et al 2020
“Transformers Play Chess ”, Cheng 2020
“A Very Unlikely Chess Game ”, Alexander 2020
“Reinforcement Learning Upside Down: Don’t Predict Rewards—Just Map Them to Actions ”, Schmidhuber 2019
Reinforcement Learning Upside Down: Don’t Predict Rewards—Just Map Them to Actions
“Training Agents Using Upside-Down Reinforcement Learning (UDRL) ”, Srivastava et al 2019
Training Agents using Upside-Down Reinforcement Learning (UDRL)
“Reward Hacking Behavior Can Generalize across Tasks ”
“Evidence of Learned Look-Ahead in a Chess-Playing Neural Network ”
Evidence of Learned Look-Ahead in a Chess-Playing Neural Network :
“Interview With Robert Kralisch on Simulators ”
“TalkRL: The Reinforcement Learning Podcast: Aravind Srinivas 2: Aravind Srinivas, Research Scientist at OpenAI, Returns to Talk Decision Transformer, VideoGPT, Choosing Problems, and Explore vs Exploit in Research Careers ”
“Supplementary Video for Do As I Can, Not As I Say: Grounding Language in Robotic Affordances ”
Supplementary video for Do As I Can, Not As I Say: Grounding Language in Robotic Affordances :
Sort By Magic
Annotations sorted by machine learning into inferred 'tags'. This provides an alternative way to browse: instead of by date order, one can browse in topic order. The 'sorted' list has been automatically clustered into multiple sections & auto-labeled for easier browsing.
Beginning with the newest annotation, it uses the embedding of each annotation to attempt to create a list of nearest-neighbor annotations, creating a progression of topics. For more details, see the link.
decision-automation
reinforcement-text generative-chess language-reward controllable-models offline-ai emergent-representations
trajectory-synthesis decision-planning sequence-modeling multi-agent diffusion-planning trajectory-transformer
upside-down-rl
Miscellaneous
https://adamkarvonen.github.io/machine_learning/2024/03/20/chess-gpt-interventions.html:https://research.google/blog/training-generalist-agents-with-multi-game-decision-transformers/https://sites.google.com/view/multi-game-transformers:View HTML (22MB):
/doc/www/sites.google.com/2dbf2c3b6b6ec9ebae5f727ce473c1db01c6bbc9.htmlhttps://www.lesswrong.com/posts/D7PumeYTDPfBTp3i7/the-waluigi-effect-mega-posthttps://www.lesswrong.com/posts/ukTLGe5CQq9w8FMne/inducing-unprompted-misalignment-in-llms
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2308.09175#deepmind: “Diversifying AI: Towards Creative Chess With AlphaZero (AZdb) ”,https://arxiv.org/abs/2306.14892: “Supervised Pretraining Can Learn In-Context Reinforcement Learning ”,https://arxiv.org/pdf/2305.18290#page=10: “DPO § 6.4: Validating GPT-4 Judgments With Human Judgments ”,https://arxiv.org/abs/2209.12892: “g.pt: Learning to Learn With Generative Models of Neural Network Checkpoints ”,https://arxiv.org/abs/2208.10291: “Trajectory Autoencoding Planner: Efficient Planning in a Compact Latent Action Space ”,https://arxiv.org/abs/2206.13499: “Prompting Decision Transformer for Few-Shot Policy Generalization ”,https://openreview.net/forum?id=0ZbPmmB61g#google: “Boosting Search Engines With Interactive Agents ”,https://arxiv.org/abs/2205.14953: “MAT: Multi-Agent Reinforcement Learning Is a Sequence Modeling Problem ”,https://arxiv.org/abs/2205.15241#google: “Multi-Game Decision Transformers ”,https://arxiv.org/abs/2205.06175#deepmind: “Gato: A Generalist Agent ”,https://arxiv.org/abs/2202.07415#deepmind: “NeuPL: Neural Population Learning ”,https://trajectory-transformer.github.io/: “Trajectory Transformer: Reinforcement Learning As One Big Sequence Modeling Problem ”,https://sites.google.com/berkeley.edu/decision-transformer: “Decision Transformer: Reinforcement Learning via Sequence Modeling ”,https://arxiv.org/abs/2104.11980: “Baller2vec++: A Look-Ahead Multi-Entity Transformer For Modeling Coordinated Agents ”,https://github.com/ricsonc/transformers-play-chess/blob/master/README.md: “Transformers Play Chess ”,https://slatestarcodex.com/2020/01/06/a-very-unlikely-chess-game/: “A Very Unlikely Chess Game ”,