‘AI hardware’ directory
- See Also
- Gwern
- Links
- “Alphabet, Nvidia Invest in OpenAI Co-Founder Sutskever’s SSI, Source Says ”, Cai & Hu 2025
- “What’s Wrong With Apple? Even Before the Threat of President Trump’s Tariffs, There Were Questions about the Company’s Inability to Make Good on New Ideas ”, Mickle 2025
- “Pre-Training GPT-4.5 ”, Tootoonchian et al 2025
- “OpenAI’s First Stargate Site to Hold Up to 400,000 Nvidia Chips ”, Ford et al 2025
- “Measuring Automated Kernel Engineering ”
- “How To Scale Your Model on TPUs ”, Austin et al 2025
- “Learning-By-Doing in the Semiconductor Industry ”, Decker 2025
- “Cerebras Launches World’s Fastest DeepSeek R1 Llama-70B Inference ”, Wang 2025
- “Neuromorphic Computing at Scale ”, Kudithipudi et al 2025
- “Good Things Come in Small Packages: Should We Adopt Lite-GPUs in AI Infrastructure? ”, Canakci et al 2025
- “Christophe Fouquet, CEO ASML: ‘Je Moest Eens Weten Hoeveel Fuck-Ups Er Nodig Zijn Om De Meest Complexe Machine Ter Wereld Te Maken’—NRC ”
- “Why a US AI "Manhattan Project" Could Backfire: Notes from Conversations in China ”, Todd 2024
- “Getting AI Datacenters in the UK: Why the UK Needs to Create Special Compute Zones; and How to Do It ”, Wiseman et al 2024
- “The Future of Compute: Nvidia’s Crown Is Slipping ”, Dagarwal 2024
- “Jake Sullivan: The American Who Waged a Tech War on China ”
- “Nvidia’s AI Chips Are Cheaper to Rent in China Than US: Supply of Processors Helps Chinese Start-Ups Advance Artificial Intelligence Technology despite Washington’s Restrictions ”, McMorrow & Olcott 2024
- “Benchmarking the Performance of Large Language Models on the Cerebras Wafer Scale Engine ”, Zhang et al 2024
- “Chips or Not, Chinese AI Pushes Ahead: A Host of Chinese AI Startups Are Attempting to Write More Efficient Code for Large Language Models ”, Kao & Huang 2024
- “Can AI Scaling Continue Through 2030? ”, Sevilla et al 2024
- “UK Government Shelves £1.3bn UK Tech and AI Plans ”
- “OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training ”, Jaghouar et al 2024
- “Huawei Faces Production Challenges With 20% Yield Rate for AI Chip ”, Trendforce 2024
- “RAM Is Practically Endless Now ”, fxtentacles 2024
- “Huawei ‘Unable to Secure 3.5 Nanometer Chips’ ”, Choi 2024
- “China Is Losing the Chip War: Xi Jinping Picked a Fight over Semiconductor Technology—One He Can’t Win ”, Schuman 2024
- “Scalable Matmul-Free Language Modeling ”, Zhu et al 2024
- “Elon Musk Ordered Nvidia to Ship Thousands of AI Chips Reserved for Tesla to Twitter/xAI ”, Kolodny 2024
- “Earnings Call: Tesla Discusses Q1 2024 Challenges and AI Expansion ”, Abdulkadir 2024
- “Microsoft, OpenAI Plan $100 Billion Data-Center Project, Media Report Says ”, Reuters 2024
- “AI and Memory Wall ”, Gholami et al 2024
- “Singapore’s Temasek in Discussions to Invest in OpenAI: State-Backed Group in Talks With ChatGPT Maker’s Chief Sam Altman Who Is Seeking Funding to Build Chips Business ”, Murgia & Ruehl 2024
- “China’s Military and Government Acquire Nvidia Chips despite US Ban ”, Baptista 2024
- “Generative AI Beyond LLMs: System Implications of Multi-Modal Generation ”, Golden et al 2023
- “Real-Time AI & The Future of AI Hardware ”, Uberti 2023
- “How Jensen Huang’s Nvidia Is Powering the AI Revolution: The Company’s CEO Bet It All on a New Kind of Chip. Now That Nvidia Is One of the Biggest Companies in the World, What Will He Do Next? ”, Witt 2023
- “OpenAI Agreed to Buy $51 Million of AI Chips From a Startup Backed by CEO Sam Altman ”, Dave 2023
- “Microsoft Swallows OpenAI’s Core Team § Compute Is King ”, Patel & Nishball 2023
- “Altman Sought Billions For Chip Venture Before OpenAI Ouster: Altman Was Fundraising in the Middle East for New Chip Venture; The Project, Code-Named Tigris, Is Intended to Rival Nvidia ”, Ludlow & Vance 2023
- “DiLoCo: Distributed Low-Communication Training of Language Models ”, Douillard et al 2023
- “LSS Transformer: Ultra-Long Sequence Distributed Transformer ”, Wang et al 2023
- “ChipNeMo: Domain-Adapted LLMs for Chip Design ”, Liu et al 2023
- wagieeacc @ "2023-10-17"
- “Saudi-China Collaboration Raises Concerns about Access to AI Chips: Fears Grow at Gulf Kingdom’s Top University That Ties to Chinese Researchers Risk Upsetting US Government ”, Kerr et al 2023
- “Efficient Video and Audio Processing With Loihi 2 ”, Shrestha et al 2023
- “Biden Is Beating China on Chips. It May Not Be Enough. ”, Wang 2023
- “Deep Mind’s Chief on AI’s Dangers—And the UK’s £900 Million Supercomputer: Demis Hassabis Says We Shouldn’t Let AI Fall into the Wrong Hands and the Government’s Plan to Build a Supercomputer for AI Is Likely to Be out of Date Before It Has Even Started ”, Sellman 2023
- “Inflection AI Announces $1.3 Billion of Funding Led by Current Investors, Microsoft, and NVIDIA ”, AI 2023
- “U.S. Considers New Curbs on AI Chip Exports to China: Restrictions Come amid Concerns That China Could Use AI Chips from Nvidia and Others for Weapon Development and Hacking ”, Fitch et al 2023
- “Unleashing True Utility Computing With Quicksand ”, Ruan et al 2023
- “The AI Boom Runs on Chips, but It Can’t Get Enough: ‘It’s like Toilet Paper during the Pandemic.’ Startups, Investors Scrounge for Computational Firepower ”, Seetharaman & Dotan 2023
- “Cerebras Architecture Deep Dive: First Look Inside the HW/SW Co-Design for Deep Learning [Updated] ”, Lie 2023
- “Big-PERCIVAL: Exploring the Native Use of 64-Bit Posit Arithmetic in Scientific Computing ”, Mallasén et al 2023
- “Accelerating Large GPT Training With Sparse Pre-Training and Dense Fine-Tuning ”, Thangarasa 2023
- davidtayar5 @ "2023-02-10"
- “SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient ”, Ryabinin et al 2023
- “Microsoft and OpenAI Extend Partnership ”, Microsoft 2023
- “A 64-Core Mixed-Signal In-Memory Compute Chip Based on Phase-Change Memory for Deep Neural Network Inference ”, Gallo et al 2022
- “MultiRay: Optimizing Efficiency for Large-Scale AI Models ”, Gupta et al 2022
- “Efficiently Scaling Transformer Inference ”, Pope et al 2022
- “Reserve Capacity of NVIDIA HGX H100s on CoreWeave Now: Available at Scale in Q1 2023 Starting at $2.23/hr ”, CoreWeave 2022
- “Petals: Collaborative Inference and Fine-Tuning of Large Models ”, Borzunov et al 2022
- “Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training ”, You et al 2022
- “Is Integer Arithmetic Enough for Deep Learning Training? ”, Ghaffari et al 2022
- “Efficient NLP Inference at the Edge via Elastic Pipelining ”, Guo et al 2022
- “Training Transformers Together ”, Borzunov et al 2022
- “Tutel: Adaptive Mixture-Of-Experts at Scale ”, Hwang et al 2022
- “8-Bit Numerical Formats for Deep Neural Networks ”, Noune et al 2022
- “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers ”, Yao et al 2022
- “FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness ”, Dao et al 2022
- “A Low-Latency Communication Design for Brain Simulations ”, Du 2022
- “Reducing Activation Recomputation in Large Transformer Models ”, Korthikanti et al 2022
- “What Language Model to Train If You Have One Million GPU Hours? ”, Scao et al 2022
- “Monarch: Expressive Structured Matrices for Efficient and Accurate Training ”, Dao et al 2022
- “Pathways: Asynchronous Distributed Dataflow for ML ”, Barham et al 2022
- “LiteTransformerSearch: Training-Free Neural Architecture Search for Efficient Language Models ”, Javaheripi et al 2022
- “Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads ”, Shukla et al 2022
- “Maximizing Communication Efficiency for Large-Scale Training via 0/1 Adam ”, Lu et al 2022
- “Introducing the AI Research SuperCluster—Facebook’s Cutting-Edge AI Supercomputer for AI Research ”, Lee & Sengupta 2022
- “Is Programmable Overhead Worth The Cost? How Much Do We Pay for a System to Be Programmable? It Depends upon Who You Ask ”, Bailey 2022
- “Spiking Neural Networks and Their Applications: A Review ”, Yamazaki et al 2022
- “On the Working Memory of Humans and Great Apes: Strikingly Similar or Remarkably Different? ”, Read et al 2021
- “Sustainable AI: Environmental Implications, Challenges and Opportunities ”, Wu et al 2021
- “China Has Already Reached Exascale—On Two Separate Systems ”, Hemsoth 2021
- “The Efficiency Misnomer ”, Dehghani et al 2021
- “Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning ”, Rudin et al 2021
- “WarpDrive: Extremely Fast End-To-End Deep Multi-Agent Reinforcement Learning on a GPU ”, Lan et al 2021
- “Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning ”, Makoviychuk et al 2021
- “PatrickStar: Parallel Training of Pre-Trained Models via Chunk-Based Memory Management ”, Fang et al 2021
- “Demonstration of Decentralized, Physics-Driven Learning ”, Dillavou et al 2021
- “Chimera: Efficiently Training Large-Scale Neural Networks With Bidirectional Pipelines ”, Li & Hoefler 2021
- “First-Generation Inference Accelerator Deployment at Facebook ”, Anderson et al 2021
- “Single-Chip Photonic Deep Neural Network for Instantaneous Image Classification ”, Ashtiani et al 2021
- “Distributed Deep Learning in Open Collaborations ”, Diskin et al 2021
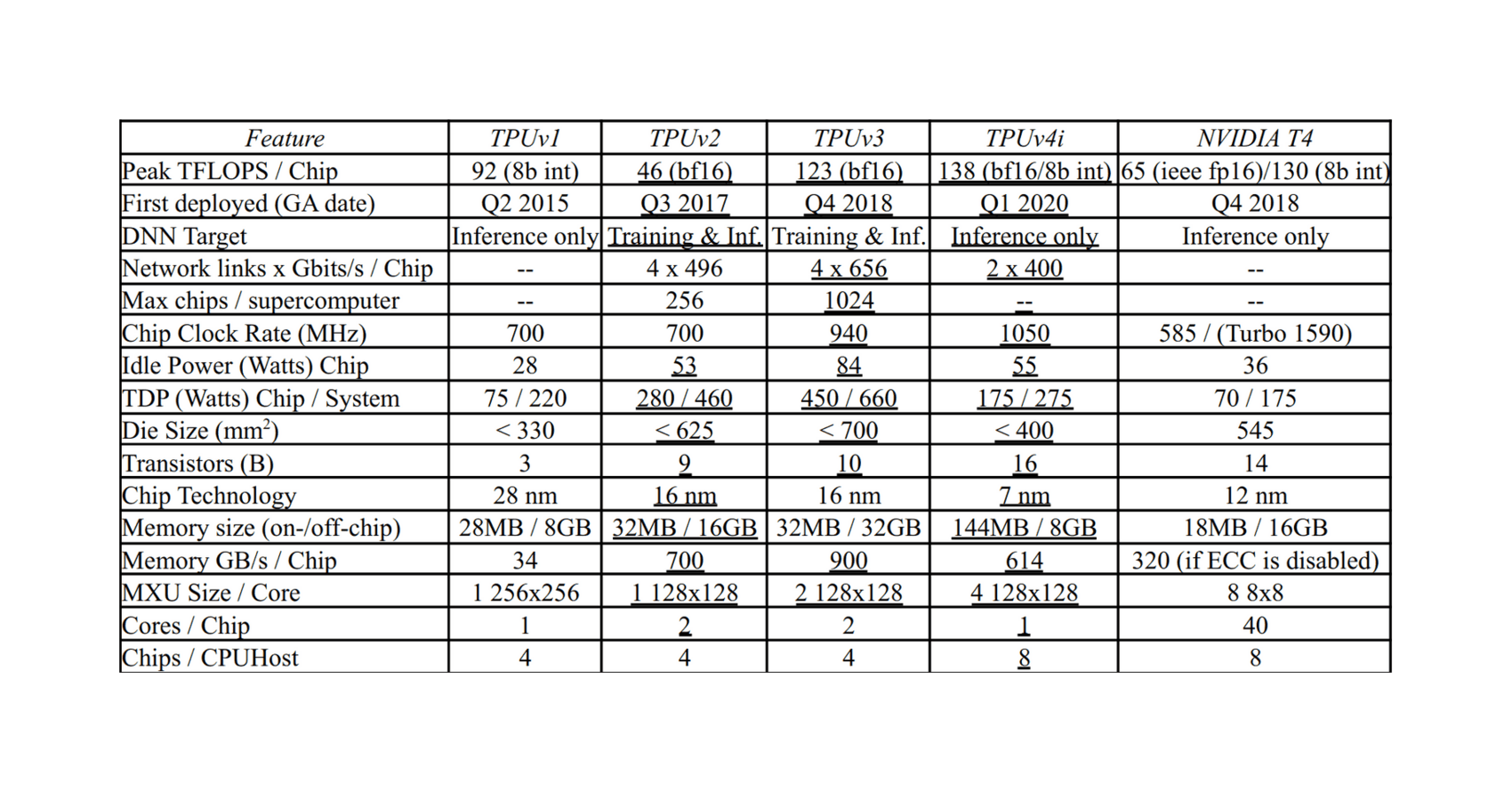
- “Ten Lessons From Three Generations Shaped Google’s TPUv4i ”, Jouppi et al 2021
- “Maximizing 3-D Parallelism in Distributed Training for Huge Neural Networks ”, Bian et al 2021
- “2.5-Dimensional Distributed Model Training ”, Wang et al 2021
- “A Full-Stack Accelerator Search Technique for Vision Applications ”, Zhang et al 2021
- “ChinAI #141: The PanGu Origin Story: Notes from an Informative Zhihu Thread on PanGu ”, Ding 2021
- “GSPMD: General and Scalable Parallelization for ML Computation Graphs ”, Xu et al 2021
- “PanGu-Α: Large-Scale Autoregressive Pretrained Chinese Language Models With Auto-Parallel Computation ”, Zeng et al 2021
- “ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning ”, Rajbhandari et al 2021
- “How to Train BERT With an Academic Budget ”, Izsak et al 2021
- “Podracer Architectures for Scalable Reinforcement Learning ”, Hessel et al 2021
- “High-Performance, Distributed Training of Large-Scale Deep Learning Recommendation Models (DLRMs) ”, Mudigere et al 2021
- “An Efficient 2D Method for Training Super-Large Deep Learning Models ”, Xu et al 2021
- “Efficient Large-Scale Language Model Training on GPU Clusters ”, Narayanan et al 2021
- “Large Batch Simulation for Deep Reinforcement Learning ”, Shacklett et al 2021
- “Warehouse-Scale Video Acceleration (Argos): Co-Design and Deployment in the Wild ”, Ranganathan et al 2021
- “TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models ”, Li et al 2021
- “PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transformers ”, He et al 2021
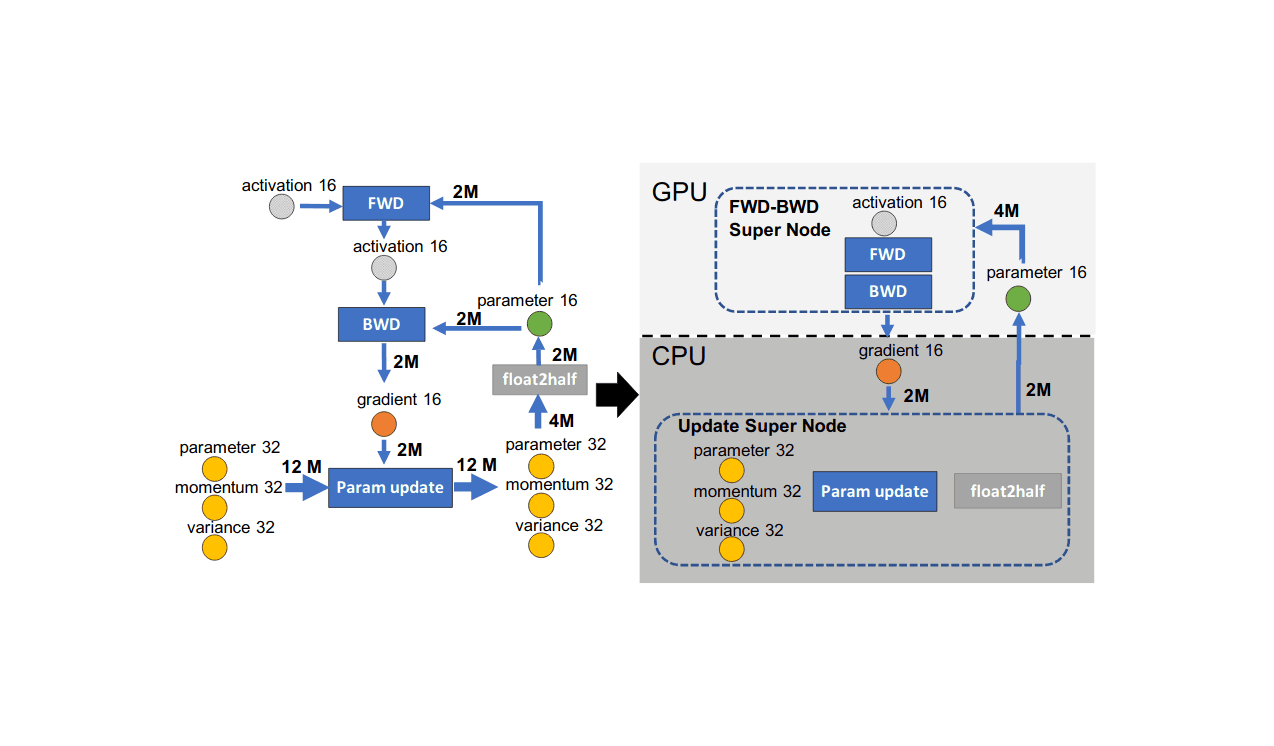
- “ZeRO-Offload: Democratizing Billion-Scale Model Training ”, Ren et al 2021
- “The Design Process for Google’s Training Chips: TPUv2 and TPUv3 ”, Norrie et al 2021
- “Hardware Beyond Backpropagation: a Photonic Co-Processor for Direct Feedback Alignment ”, Launay et al 2020
- “Parallel Training of Deep Networks With Local Updates ”, Laskin et al 2020
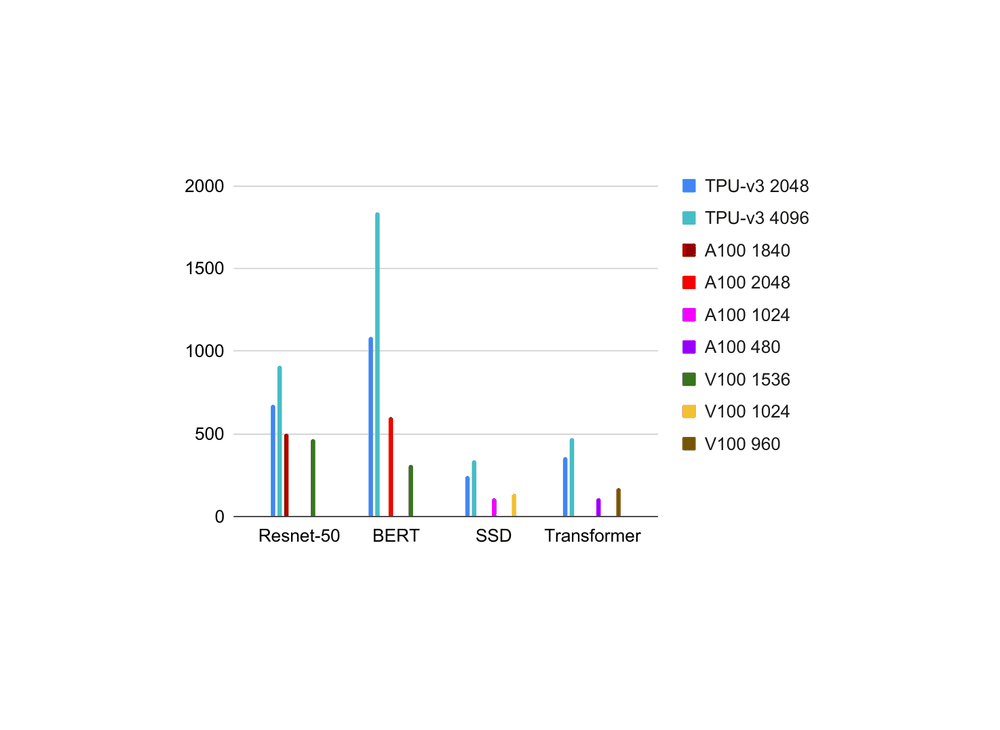
- “Exploring the Limits of Concurrency in ML Training on Google TPUs ”, Kumar et al 2020
- “BytePS: A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters ”, Jiang et al 2020
- “Training EfficientNets at Supercomputer Scale: 83% ImageNet Top-1 Accuracy in One Hour ”, Wongpanich et al 2020
- “Matrix Engines for High Performance Computing:A Paragon of Performance or Grasping at Straws? ”, Domke et al 2020
- “Direct Feedback Alignment Scales to Modern Deep Learning Tasks and Architectures ”, Launay et al 2020b
- “Interlocking Backpropagation: Improving Depthwise Model-Parallelism ”, Gomez et al 2020
- “DeepSpeed: Extreme-Scale Model Training for Everyone ”, Team et al 2020
- “Measuring Hardware Overhang ”, Hippke 2020
- “The Node Is Nonsense: There Are Better Ways to Measure Progress Than the Old Moore’s Law Metric ”, Moore 2020
- “Are We in an AI Overhang? ”, Jones 2020
- “HOBFLOPS CNNs: Hardware Optimized Bitslice-Parallel Floating-Point Operations for Convolutional Neural Networks ”, Garland & Gregg 2020
- “The Computational Limits of Deep Learning ”, Thompson et al 2020
- “Data Movement Is All You Need: A Case Study on Optimizing Transformers ”, Ivanov et al 2020
- “PyTorch Distributed: Experiences on Accelerating Data Parallel Training ”, Li et al 2020
- “Japanese Supercomputer Is Crowned World’s Speediest: In the Race for the Most Powerful Computers, Fugaku, a Japanese Supercomputer, Recently Beat American and Chinese Machines ”, Clark 2020
- “Sample Factory: Egocentric 3D Control from Pixels at 100,000 FPS With Asynchronous Reinforcement Learning ”, Petrenko et al 2020
- “PipeDream-2BW: Memory-Efficient Pipeline-Parallel DNN Training ”, Narayanan et al 2020
- “There’s Plenty of Room at the Top: What Will Drive Computer Performance After Moore’s Law? ”, Leiserson et al 2020
- “A Domain-Specific Supercomputer for Training Deep Neural Networks ”, Jouppi et al 2020
- “Microsoft Announces New Supercomputer, Lays out Vision for Future AI Work ”, Langston 2020
- “AI and Efficiency: We’re Releasing an Analysis Showing That Since 2012 the Amount of Compute Needed to Train a Neural Net to the Same Performance on ImageNet Classification Has Been Decreasing by a Factor of 2 Every 16 Months ”, Hernandez & Brown 2020
- “Computation in the Human Cerebral Cortex Uses Less Than 0.2 Watts yet This Great Expense Is Optimal When considering Communication Costs ”, Levy & Calvert 2020
- “Startup Tenstorrent Shows AI Is Changing Computing and vice Versa: Tenstorrent Is One of the Rush of AI Chip Makers Founded in 2016 and Finally Showing Product. The New Wave of Chips Represent a Substantial Departure from How Traditional Computer Chips Work, but Also Point to Ways That Neural Network Design May Change in the Years to Come ”, Ray 2020
- “AI Chips: What They Are and Why They Matter—An AI Chips Reference ”, Khan & Mann 2020
- “2019 Recent Trends in GPU Price per FLOPS ”, Bergal 2020
- “Pipelined Backpropagation at Scale: Training Large Models without Batches ”, Kosson et al 2020
- “Ultrafast Machine Vision With 2D Material Neural Network Image Sensors ”, Mennel et al 2020
- “L2L: Training Large Neural Networks With Constant Memory Using a New Execution Algorithm ”, Pudipeddi et al 2020
- “Towards Spike-Based Machine Intelligence With Neuromorphic Computing ”, Roy et al 2019
- “Checkmate: Breaking the Memory Wall With Optimal Tensor Rematerialization ”, Jain et al 2019
- “Training Kinetics in 15 Minutes: Large-Scale Distributed Training on Videos ”, Lin et al 2019
- “Energy and Policy Considerations for Deep Learning in NLP ”, Strubell et al 2019
- “Large Batch Optimization for Deep Learning: Training BERT in 76 Minutes ”, You et al 2019
- “GAP: Generalizable Approximate Graph Partitioning Framework ”, Nazi et al 2019
- “An Empirical Model of Large-Batch Training ”, McCandlish et al 2018
- “Bayesian Layers: A Module for Neural Network Uncertainty ”, Tran et al 2018
- “GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism ”, Huang et al 2018
- “Measuring the Effects of Data Parallelism on Neural Network Training ”, Shallue et al 2018
- “Mesh-TensorFlow: Deep Learning for Supercomputers ”, Shazeer et al 2018
- “There Is Plenty of Time at the Bottom: the Economics, Risk and Ethics of Time Compression ”, Sandberg 2018
- “Highly Scalable Deep Learning Training System With Mixed-Precision: Training ImageNet in 4 Minutes ”, Jia et al 2018
- “AI and Compute ”, Amodei et al 2018
- “Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions ”, Vasilache et al 2018
- “Loihi: A Neuromorphic Manycore Processor With On-Chip Learning ”, Davies et al 2018
- “Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training ”, Lin et al 2017
- “Mixed Precision Training ”, Micikevicius et al 2017
- “On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima ”, Keskar et al 2016
- “Training Deep Nets With Sublinear Memory Cost ”, Chen et al 2016
- “GeePS: Scalable Deep Learning on Distributed GPUs With a GPU-Specialized Parameter Server ”, Cui et al 2016
- “Convolutional Networks for Fast, Energy-Efficient Neuromorphic Computing ”, Esser et al 2016
- “Communication-Efficient Learning of Deep Networks from Decentralized Data ”, McMahan et al 2016
- “Persistent RNNs: Stashing Recurrent Weights On-Chip ”, Diamos et al 2016
- “The Brain As a Universal Learning Machine ”, Cannell 2015
- “Scaling Distributed Machine Learning With the Parameter Server ”, Li et al 2014
- “Multi-Column Deep Neural Network for Traffic Sign Classification ”, Cireşan et al 2012b
- “Multi-Column Deep Neural Networks for Image Classification ”, Cireşan et al 2012
- “Building High-Level Features Using Large Scale Unsupervised Learning ”, Le et al 2011
- “Implications of Historical Trends in the Electrical Efficiency of Computing ”, Koomey et al 2011
- “HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent ”, Niu et al 2011
- “DanNet: Flexible, High Performance Convolutional Neural Networks for Image Classification ”, Ciresan et al 2011
- “Goodbye 2010 ”, Legg 2010
- “Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition ”, Ciresan et al 2010
- “The Cat Is out of the Bag: Cortical Simulations With 109 Neurons, 1013 Synapses ”, Ananthanarayanan et al 2009
- “Large-Scale Deep Unsupervised Learning Using Graphics Processors ”, Raina et al 2009
- “Bandwidth Optimal All-Reduce Algorithms for Clusters of Workstations ”, Patarasuk & Yuan 2009
- “Whole Brain Emulation: A Roadmap ”
- “Moore’s Law and the Technology S-Curve ”, Bowden 2004
- “DARPA and the Quest for Machine Intelligence, 1983–1993 ”, Roland & Shiman 2002
- “Ultimate Physical Limits to Computation ”, Lloyd 1999
- “Matrioshka Brains ”
- “When Will Computer Hardware Match the Human Brain? ”, Moravec 1998
- “Superhumanism: According to Hans Moravec § AI Scaling ”, Platt 1995
- “A Sociological Study of the Official History of the Perceptrons Controversy [1993] ”, Olazaran 1993
- “Intelligence As an Emergent Behavior; Or, The Songs of Eden ”, Hillis 1988
- “Computing With Connections ”, Sejnowski 1987
- “The Role Of RAW POWER In INTELLIGENCE ”, Moravec 1976
- “Brain Performance in FLOPS ”
- “Google Demonstrates Leading Performance in Latest MLPerf Benchmarks ”
- “H100 GPUs Set Standard for Gen AI in Debut MLPerf Benchmark ”
- “Introducing Cerebras Inference: AI at Instant Speed ”, Cerebras 2025
- “Llama-3.1-405B Now Runs at 969 Tokens/s on Cerebras Inference ”
- “Cerebras Systems Unveils World’s Fastest AI Chip With Whopping 4 Trillion Transistors ”
- “Crusoe Expands AI Data Center Campus in Abilene to 1.2 Gigawatts ”
- “NVIDIA Hopper Architecture In-Depth ”
- “AI Progress Is about to Speed Up ”
- “Trends in GPU Price-Performance ”
- “NVIDIA/Megatron-LM: Ongoing Research Training Transformer Models at Scale ”
- “12 Hours Later, Groq Deploys Llama-3-Instruct (8 & 70B) ”
- “The Technology Behind BLOOM Training ”
- “From Bare Metal to a 70B Model: Infrastructure Set-Up and Scripts ”
- “AI Accelerators, Part IV: The Very Rich Landscape ”, Fuchs 2025
- “NVIDIA Announces DGX H100 Systems – World’s Most Advanced Enterprise AI Infrastructure ”
- “NVIDIA Launches UK’s Most Powerful Supercomputer, for Research in AI and Healthcare ”
- “Perlmutter, Said to Be the World’s Fastest AI Supercomputer, Comes Online ”
- “TensorFlow Research Cloud (TRC): Accelerate Your Cutting-Edge Machine Learning Research With Free Cloud TPUs ”, TRC 2025
- “Cerebras’ Tech Trains "Brain-Scale" AIs ”
- “Fugaku Holds Top Spot, Exascale Remains Elusive ”
- “342 Transistors for Every Person In the World: Cerebras 2nd Gen Wafer Scale Engine Teased ”
- “Jim Keller Becomes CTO at Tenstorrent: ‘The Most Promising Architecture Out There’ ”
- “NVIDIA Unveils Grace: A High-Performance Arm Server CPU For Use In Big AI Systems ”
- “Cerebras Unveils Wafer Scale Engine Two (WSE2): 2.6 Trillion Transistors, 100% Yield ”
- “AMD Announces Instinct MI200 Accelerator Family: Taking Servers to Exascale and Beyond ”
- “NVIDIA Hopper GPU Architecture and H100 Accelerator Announced: Working Smarter and Harder ”
- “Biological Anchors: A Trick That Might Or Might Not Work ”
- “Scaling Up and Out: Training Massive Models on Cerebras Systems Using Weight Streaming ”
- “DeepSeek: The Quiet Giant Leading China’s AI Race ”
- “DeepSeek: The View from China ”
- “DeepSeek’s Edge ”
- “Fermi Estimate of Future Training Runs ”
- “Carl Shulman #2: AI Takeover, Bio & Cyber Attacks, Detecting Deception, & Humanity's Far Future ”
- “Etched Is Making the Biggest Bet in AI ”
- “The Emerging Age of AI Diplomacy: To Compete With China, the United States Must Walk a Tightrope in the Gulf ”
- “How Far Can AI Progress Before Hitting Effective Physical Limits? ”
- “The Resilience Myth: Fatal Flaws in the Push to Secure Chip Supply Chains ”
- “Prime Minister Sets out Blueprint to Turbocharge AI ”
- “Compute Funds and Pre-Trained Models ”
- “The Next Big Thing: Introducing IPU-POD128 and IPU-POD256 ”
- “The WoW Factor: Graphcore Systems Get Huge Power and Efficiency Boost ”
- “AWS Enables 4,000-GPU UltraClusters With New P4 A100 Instances ”
- “Estimating Training Compute of Deep Learning Models ”
- “What O3 Becomes by 2028 ”, Nesov 2025
- “The Colliding Exponentials of AI ”
- “Moore’s Law, AI, and the pace of Progress ”
- “How Fast Can We Perform a Forward Pass? ”
- “"AI and Compute" Trend Isn’t Predictive of What Is Happening ”
- “Brain Efficiency: Much More Than You Wanted to Know ”
- “DeepSpeed: Accelerating Large-Scale Model Inference and Training via System Optimizations and Compression ”
- “ZeRO-Infinity and DeepSpeed: Unlocking Unprecedented Model Scale for Deep Learning Training ”
- “The World’s Largest Computer Chip ”
- “The Billion Dollar AI Problem That Just Keeps Scaling ”
- “TSMC Confirms 3nm Tech for 2022, Could Enable Epic 80 Billion Transistor GPUs ”
- “ORNL’s Frontier First to Break the Exaflop Ceiling ”
- “A Spymaster Sheikh Controls a $1.5 Trillion Fortune. Tahnoun Bin Zayed Al Nahyan Wants to Use It to Dominate AI ”
- “Returning to Google DeepMind ”, Tay 2025
- “How to Accelerate Innovation With AI at Scale ”
- “48:44—Tesla Vision • 1:13:12—Planning and Control • 1:24:35—Manual Labeling • 1:28:11—Auto Labeling • 1:35:15—Simulation • 1:42:10—Hardware Integration • 1:45:40—Dojo ”
- ID_AA_Carmack
- lepikhin
- Wikipedia (16)
- Miscellaneous
- Bibliography
See Also
Gwern
“LLMs Can Be Faster Than You Think ”, Gwern 2025
“Hardware Hedging Scaling Risks ”, Gwern 2024
“Computer Optimization: Your Computer Is Faster Than You Think ”, Gwern 2021
Computer Optimization: Your Computer Is Faster Than You Think
“Slowing Moore’s Law: How It Could Happen ”, Gwern 2012
Links
“Alphabet, Nvidia Invest in OpenAI Co-Founder Sutskever’s SSI, Source Says ”, Cai & Hu 2025
Alphabet, Nvidia invest in OpenAI co-founder Sutskever’s SSI, source says
“What’s Wrong With Apple? Even Before the Threat of President Trump’s Tariffs, There Were Questions about the Company’s Inability to Make Good on New Ideas ”, Mickle 2025
“Pre-Training GPT-4.5 ”, Tootoonchian et al 2025
“OpenAI’s First Stargate Site to Hold Up to 400,000 Nvidia Chips ”, Ford et al 2025
OpenAI’s First Stargate Site to Hold Up to 400,000 Nvidia Chips
“Measuring Automated Kernel Engineering ”
“How To Scale Your Model on TPUs ”, Austin et al 2025
“Learning-By-Doing in the Semiconductor Industry ”, Decker 2025
“Cerebras Launches World’s Fastest DeepSeek R1 Llama-70B Inference ”, Wang 2025
Cerebras Launches World’s Fastest DeepSeek R1 Llama-70B Inference
“Neuromorphic Computing at Scale ”, Kudithipudi et al 2025
“Good Things Come in Small Packages: Should We Adopt Lite-GPUs in AI Infrastructure? ”, Canakci et al 2025
Good things come in small packages: Should we adopt Lite-GPUs in AI infrastructure?
“Christophe Fouquet, CEO ASML: ‘Je Moest Eens Weten Hoeveel Fuck-Ups Er Nodig Zijn Om De Meest Complexe Machine Ter Wereld Te Maken’—NRC ”
“Why a US AI "Manhattan Project" Could Backfire: Notes from Conversations in China ”, Todd 2024
Why a US AI "Manhattan Project" could backfire: notes from conversations in China
“Getting AI Datacenters in the UK: Why the UK Needs to Create Special Compute Zones; and How to Do It ”, Wiseman et al 2024
Getting AI datacenters in the UK: Why the UK needs to create Special Compute Zones; and how to do it
“The Future of Compute: Nvidia’s Crown Is Slipping ”, Dagarwal 2024
“Jake Sullivan: The American Who Waged a Tech War on China ”
Jake Sullivan: The American Who Waged a Tech War on China :
View External Link:
https://www.wired.com/story/jake-sullivan-china-tech-profile/
“Nvidia’s AI Chips Are Cheaper to Rent in China Than US: Supply of Processors Helps Chinese Start-Ups Advance Artificial Intelligence Technology despite Washington’s Restrictions ”, McMorrow & Olcott 2024
“Benchmarking the Performance of Large Language Models on the Cerebras Wafer Scale Engine ”, Zhang et al 2024
Benchmarking the Performance of Large Language Models on the Cerebras Wafer Scale Engine
“Chips or Not, Chinese AI Pushes Ahead: A Host of Chinese AI Startups Are Attempting to Write More Efficient Code for Large Language Models ”, Kao & Huang 2024
“Can AI Scaling Continue Through 2030? ”, Sevilla et al 2024
“UK Government Shelves £1.3bn UK Tech and AI Plans ”
“OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training ”, Jaghouar et al 2024
OpenDiLoCo: An Open-Source Framework for Globally Distributed Low-Communication Training
“Huawei Faces Production Challenges With 20% Yield Rate for AI Chip ”, Trendforce 2024
Huawei Faces Production Challenges with 20% Yield Rate for AI Chip
“RAM Is Practically Endless Now ”, fxtentacles 2024
“Huawei ‘Unable to Secure 3.5 Nanometer Chips’ ”, Choi 2024
“China Is Losing the Chip War: Xi Jinping Picked a Fight over Semiconductor Technology—One He Can’t Win ”, Schuman 2024
“Scalable Matmul-Free Language Modeling ”, Zhu et al 2024
“Elon Musk Ordered Nvidia to Ship Thousands of AI Chips Reserved for Tesla to Twitter/xAI ”, Kolodny 2024
Elon Musk ordered Nvidia to ship thousands of AI chips reserved for Tesla to Twitter/xAI
“Earnings Call: Tesla Discusses Q1 2024 Challenges and AI Expansion ”, Abdulkadir 2024
Earnings call: Tesla Discusses Q1 2024 Challenges and AI Expansion
“Microsoft, OpenAI Plan $100 Billion Data-Center Project, Media Report Says ”, Reuters 2024
Microsoft, OpenAI plan $100 billion data-center project, media report says
“AI and Memory Wall ”, Gholami et al 2024
“Singapore’s Temasek in Discussions to Invest in OpenAI: State-Backed Group in Talks With ChatGPT Maker’s Chief Sam Altman Who Is Seeking Funding to Build Chips Business ”, Murgia & Ruehl 2024
“China’s Military and Government Acquire Nvidia Chips despite US Ban ”, Baptista 2024
China’s military and government acquire Nvidia chips despite US ban
“Generative AI Beyond LLMs: System Implications of Multi-Modal Generation ”, Golden et al 2023
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
“Real-Time AI & The Future of AI Hardware ”, Uberti 2023
“How Jensen Huang’s Nvidia Is Powering the AI Revolution: The Company’s CEO Bet It All on a New Kind of Chip. Now That Nvidia Is One of the Biggest Companies in the World, What Will He Do Next? ”, Witt 2023
“OpenAI Agreed to Buy $51 Million of AI Chips From a Startup Backed by CEO Sam Altman ”, Dave 2023
OpenAI Agreed to Buy $51 Million of AI Chips From a Startup Backed by CEO Sam Altman
“Microsoft Swallows OpenAI’s Core Team § Compute Is King ”, Patel & Nishball 2023
“Altman Sought Billions For Chip Venture Before OpenAI Ouster: Altman Was Fundraising in the Middle East for New Chip Venture; The Project, Code-Named Tigris, Is Intended to Rival Nvidia ”, Ludlow & Vance 2023
“DiLoCo: Distributed Low-Communication Training of Language Models ”, Douillard et al 2023
DiLoCo: Distributed Low-Communication Training of Language Models
“LSS Transformer: Ultra-Long Sequence Distributed Transformer ”, Wang et al 2023
LSS Transformer: Ultra-Long Sequence Distributed Transformer
“ChipNeMo: Domain-Adapted LLMs for Chip Design ”, Liu et al 2023
wagieeacc @ "2023-10-17"
“Saudi-China Collaboration Raises Concerns about Access to AI Chips: Fears Grow at Gulf Kingdom’s Top University That Ties to Chinese Researchers Risk Upsetting US Government ”, Kerr et al 2023
“Efficient Video and Audio Processing With Loihi 2 ”, Shrestha et al 2023
“Biden Is Beating China on Chips. It May Not Be Enough. ”, Wang 2023
“Deep Mind’s Chief on AI’s Dangers—And the UK’s £900 Million Supercomputer: Demis Hassabis Says We Shouldn’t Let AI Fall into the Wrong Hands and the Government’s Plan to Build a Supercomputer for AI Is Likely to Be out of Date Before It Has Even Started ”, Sellman 2023
“Inflection AI Announces $1.3 Billion of Funding Led by Current Investors, Microsoft, and NVIDIA ”, AI 2023
Inflection AI announces $1.3 billion of funding led by current investors, Microsoft, and NVIDIA
“U.S. Considers New Curbs on AI Chip Exports to China: Restrictions Come amid Concerns That China Could Use AI Chips from Nvidia and Others for Weapon Development and Hacking ”, Fitch et al 2023
“Unleashing True Utility Computing With Quicksand ”, Ruan et al 2023
“The AI Boom Runs on Chips, but It Can’t Get Enough: ‘It’s like Toilet Paper during the Pandemic.’ Startups, Investors Scrounge for Computational Firepower ”, Seetharaman & Dotan 2023
“Cerebras Architecture Deep Dive: First Look Inside the HW/SW Co-Design for Deep Learning [Updated] ”, Lie 2023
Cerebras Architecture Deep Dive: First Look Inside the HW/SW Co-Design for Deep Learning [Updated]
“Big-PERCIVAL: Exploring the Native Use of 64-Bit Posit Arithmetic in Scientific Computing ”, Mallasén et al 2023
Big-PERCIVAL: Exploring the Native Use of 64-Bit Posit Arithmetic in Scientific Computing
“Accelerating Large GPT Training With Sparse Pre-Training and Dense Fine-Tuning ”, Thangarasa 2023
Accelerating Large GPT Training with Sparse Pre-Training and Dense Fine-Tuning
davidtayar5 @ "2023-02-10"
Context on the NVIDIA ChatGPT opportunity—and ramifications of large language model enthusiasm
“SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient ”, Ryabinin et al 2023
SWARM Parallelism: Training Large Models Can Be Surprisingly Communication-Efficient
“Microsoft and OpenAI Extend Partnership ”, Microsoft 2023
“A 64-Core Mixed-Signal In-Memory Compute Chip Based on Phase-Change Memory for Deep Neural Network Inference ”, Gallo et al 2022
“MultiRay: Optimizing Efficiency for Large-Scale AI Models ”, Gupta et al 2022
“Efficiently Scaling Transformer Inference ”, Pope et al 2022
“Reserve Capacity of NVIDIA HGX H100s on CoreWeave Now: Available at Scale in Q1 2023 Starting at $2.23/hr ”, CoreWeave 2022
“Petals: Collaborative Inference and Fine-Tuning of Large Models ”, Borzunov et al 2022
Petals: Collaborative Inference and Fine-tuning of Large Models
“Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training ”, You et al 2022
Zeus: Understanding and Optimizing GPU Energy Consumption of DNN Training
“Is Integer Arithmetic Enough for Deep Learning Training? ”, Ghaffari et al 2022
“Efficient NLP Inference at the Edge via Elastic Pipelining ”, Guo et al 2022
“Training Transformers Together ”, Borzunov et al 2022
“Tutel: Adaptive Mixture-Of-Experts at Scale ”, Hwang et al 2022
“8-Bit Numerical Formats for Deep Neural Networks ”, Noune et al 2022
“ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers ”, Yao et al 2022
ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers
“FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness ”, Dao et al 2022
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
“A Low-Latency Communication Design for Brain Simulations ”, Du 2022
“Reducing Activation Recomputation in Large Transformer Models ”, Korthikanti et al 2022
Reducing Activation Recomputation in Large Transformer Models
“What Language Model to Train If You Have One Million GPU Hours? ”, Scao et al 2022
What Language Model to Train if You Have One Million GPU Hours?
“Monarch: Expressive Structured Matrices for Efficient and Accurate Training ”, Dao et al 2022
Monarch: Expressive Structured Matrices for Efficient and Accurate Training
“Pathways: Asynchronous Distributed Dataflow for ML ”, Barham et al 2022
“LiteTransformerSearch: Training-Free Neural Architecture Search for Efficient Language Models ”, Javaheripi et al 2022
LiteTransformerSearch: Training-free Neural Architecture Search for Efficient Language Models
“Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads ”, Shukla et al 2022
Singularity: Planet-Scale, Preemptive and Elastic Scheduling of AI Workloads
“Maximizing Communication Efficiency for Large-Scale Training via 0/1 Adam ”, Lu et al 2022
Maximizing Communication Efficiency for Large-scale Training via 0/1 Adam
“Introducing the AI Research SuperCluster—Facebook’s Cutting-Edge AI Supercomputer for AI Research ”, Lee & Sengupta 2022
Introducing the AI Research SuperCluster—Facebook’s cutting-edge AI supercomputer for AI research
“Is Programmable Overhead Worth The Cost? How Much Do We Pay for a System to Be Programmable? It Depends upon Who You Ask ”, Bailey 2022
“Spiking Neural Networks and Their Applications: A Review ”, Yamazaki et al 2022
“On the Working Memory of Humans and Great Apes: Strikingly Similar or Remarkably Different? ”, Read et al 2021
On the Working Memory of Humans and Great Apes: Strikingly Similar or Remarkably Different?
“Sustainable AI: Environmental Implications, Challenges and Opportunities ”, Wu et al 2021
Sustainable AI: Environmental Implications, Challenges and Opportunities
“China Has Already Reached Exascale—On Two Separate Systems ”, Hemsoth 2021
“The Efficiency Misnomer ”, Dehghani et al 2021
“Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning ”, Rudin et al 2021
Learning to Walk in Minutes Using Massively Parallel Deep Reinforcement Learning
“WarpDrive: Extremely Fast End-To-End Deep Multi-Agent Reinforcement Learning on a GPU ”, Lan et al 2021
WarpDrive: Extremely Fast End-to-End Deep Multi-Agent Reinforcement Learning on a GPU
“Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning ”, Makoviychuk et al 2021
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
“PatrickStar: Parallel Training of Pre-Trained Models via Chunk-Based Memory Management ”, Fang et al 2021
PatrickStar: Parallel Training of Pre-trained Models via Chunk-based Memory Management
“Demonstration of Decentralized, Physics-Driven Learning ”, Dillavou et al 2021
“Chimera: Efficiently Training Large-Scale Neural Networks With Bidirectional Pipelines ”, Li & Hoefler 2021
Chimera: Efficiently Training Large-Scale Neural Networks with Bidirectional Pipelines
“First-Generation Inference Accelerator Deployment at Facebook ”, Anderson et al 2021
First-Generation Inference Accelerator Deployment at Facebook
“Single-Chip Photonic Deep Neural Network for Instantaneous Image Classification ”, Ashtiani et al 2021
Single-chip photonic deep neural network for instantaneous image classification
“Distributed Deep Learning in Open Collaborations ”, Diskin et al 2021
“Ten Lessons From Three Generations Shaped Google’s TPUv4i ”, Jouppi et al 2021
“Maximizing 3-D Parallelism in Distributed Training for Huge Neural Networks ”, Bian et al 2021
Maximizing 3-D Parallelism in Distributed Training for Huge Neural Networks
“2.5-Dimensional Distributed Model Training ”, Wang et al 2021
“A Full-Stack Accelerator Search Technique for Vision Applications ”, Zhang et al 2021
A Full-stack Accelerator Search Technique for Vision Applications
“ChinAI #141: The PanGu Origin Story: Notes from an Informative Zhihu Thread on PanGu ”, Ding 2021
ChinAI #141: The PanGu Origin Story: Notes from an informative Zhihu Thread on PanGu
“GSPMD: General and Scalable Parallelization for ML Computation Graphs ”, Xu et al 2021
GSPMD: General and Scalable Parallelization for ML Computation Graphs
“PanGu-Α: Large-Scale Autoregressive Pretrained Chinese Language Models With Auto-Parallel Computation ”, Zeng et al 2021
“ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning ”, Rajbhandari et al 2021
ZeRO-Infinity: Breaking the GPU Memory Wall for Extreme Scale Deep Learning
“How to Train BERT With an Academic Budget ”, Izsak et al 2021
“Podracer Architectures for Scalable Reinforcement Learning ”, Hessel et al 2021
“High-Performance, Distributed Training of Large-Scale Deep Learning Recommendation Models (DLRMs) ”, Mudigere et al 2021
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models (DLRMs)
“An Efficient 2D Method for Training Super-Large Deep Learning Models ”, Xu et al 2021
An Efficient 2D Method for Training Super-Large Deep Learning Models
“Efficient Large-Scale Language Model Training on GPU Clusters ”, Narayanan et al 2021
Efficient Large-Scale Language Model Training on GPU Clusters
“Large Batch Simulation for Deep Reinforcement Learning ”, Shacklett et al 2021
“Warehouse-Scale Video Acceleration (Argos): Co-Design and Deployment in the Wild ”, Ranganathan et al 2021
Warehouse-Scale Video Acceleration (Argos): Co-design and Deployment in the Wild
“TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models ”, Li et al 2021
TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models
“PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transformers ”, He et al 2021
PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transformers
“ZeRO-Offload: Democratizing Billion-Scale Model Training ”, Ren et al 2021
“The Design Process for Google’s Training Chips: TPUv2 and TPUv3 ”, Norrie et al 2021
The Design Process for Google’s Training Chips: TPUv2 and TPUv3
“Hardware Beyond Backpropagation: a Photonic Co-Processor for Direct Feedback Alignment ”, Launay et al 2020
Hardware Beyond Backpropagation: a Photonic Co-Processor for Direct Feedback Alignment
“Parallel Training of Deep Networks With Local Updates ”, Laskin et al 2020
“Exploring the Limits of Concurrency in ML Training on Google TPUs ”, Kumar et al 2020
Exploring the limits of Concurrency in ML Training on Google TPUs
“BytePS: A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters ”, Jiang et al 2020
“Training EfficientNets at Supercomputer Scale: 83% ImageNet Top-1 Accuracy in One Hour ”, Wongpanich et al 2020
Training EfficientNets at Supercomputer Scale: 83% ImageNet Top-1 Accuracy in One Hour
“Matrix Engines for High Performance Computing:A Paragon of Performance or Grasping at Straws? ”, Domke et al 2020
Matrix Engines for High Performance Computing:A Paragon of Performance or Grasping at Straws?
“Direct Feedback Alignment Scales to Modern Deep Learning Tasks and Architectures ”, Launay et al 2020b
Direct Feedback Alignment Scales to Modern Deep Learning Tasks and Architectures
“Interlocking Backpropagation: Improving Depthwise Model-Parallelism ”, Gomez et al 2020
Interlocking Backpropagation: Improving depthwise model-parallelism
“DeepSpeed: Extreme-Scale Model Training for Everyone ”, Team et al 2020
“Measuring Hardware Overhang ”, Hippke 2020
“The Node Is Nonsense: There Are Better Ways to Measure Progress Than the Old Moore’s Law Metric ”, Moore 2020
The Node Is Nonsense: There are better ways to measure progress than the old Moore’s law metric
“Are We in an AI Overhang? ”, Jones 2020
“HOBFLOPS CNNs: Hardware Optimized Bitslice-Parallel Floating-Point Operations for Convolutional Neural Networks ”, Garland & Gregg 2020
“The Computational Limits of Deep Learning ”, Thompson et al 2020
“Data Movement Is All You Need: A Case Study on Optimizing Transformers ”, Ivanov et al 2020
Data Movement Is All You Need: A Case Study on Optimizing Transformers
“PyTorch Distributed: Experiences on Accelerating Data Parallel Training ”, Li et al 2020
PyTorch Distributed: Experiences on Accelerating Data Parallel Training
“Japanese Supercomputer Is Crowned World’s Speediest: In the Race for the Most Powerful Computers, Fugaku, a Japanese Supercomputer, Recently Beat American and Chinese Machines ”, Clark 2020
“Sample Factory: Egocentric 3D Control from Pixels at 100,000 FPS With Asynchronous Reinforcement Learning ”, Petrenko et al 2020
“PipeDream-2BW: Memory-Efficient Pipeline-Parallel DNN Training ”, Narayanan et al 2020
PipeDream-2BW: Memory-Efficient Pipeline-Parallel DNN Training
“There’s Plenty of Room at the Top: What Will Drive Computer Performance After Moore’s Law? ”, Leiserson et al 2020
There’s plenty of room at the Top: What will drive computer performance after Moore’s law?
“A Domain-Specific Supercomputer for Training Deep Neural Networks ”, Jouppi et al 2020
A domain-specific supercomputer for training deep neural networks
“Microsoft Announces New Supercomputer, Lays out Vision for Future AI Work ”, Langston 2020
Microsoft announces new supercomputer, lays out vision for future AI work
“AI and Efficiency: We’re Releasing an Analysis Showing That Since 2012 the Amount of Compute Needed to Train a Neural Net to the Same Performance on ImageNet Classification Has Been Decreasing by a Factor of 2 Every 16 Months ”, Hernandez & Brown 2020
“Computation in the Human Cerebral Cortex Uses Less Than 0.2 Watts yet This Great Expense Is Optimal When considering Communication Costs ”, Levy & Calvert 2020
“Startup Tenstorrent Shows AI Is Changing Computing and vice Versa: Tenstorrent Is One of the Rush of AI Chip Makers Founded in 2016 and Finally Showing Product. The New Wave of Chips Represent a Substantial Departure from How Traditional Computer Chips Work, but Also Point to Ways That Neural Network Design May Change in the Years to Come ”, Ray 2020
“AI Chips: What They Are and Why They Matter—An AI Chips Reference ”, Khan & Mann 2020
AI Chips: What They Are and Why They Matter—An AI Chips Reference
“2019 Recent Trends in GPU Price per FLOPS ”, Bergal 2020
“Pipelined Backpropagation at Scale: Training Large Models without Batches ”, Kosson et al 2020
Pipelined Backpropagation at Scale: Training Large Models without Batches
“Ultrafast Machine Vision With 2D Material Neural Network Image Sensors ”, Mennel et al 2020
Ultrafast machine vision with 2D material neural network image sensors :
View PDF:
“L2L: Training Large Neural Networks With Constant Memory Using a New Execution Algorithm ”, Pudipeddi et al 2020
L2L: Training Large Neural Networks with Constant Memory using a New Execution Algorithm
“Towards Spike-Based Machine Intelligence With Neuromorphic Computing ”, Roy et al 2019
Towards spike-based machine intelligence with neuromorphic computing
“Checkmate: Breaking the Memory Wall With Optimal Tensor Rematerialization ”, Jain et al 2019
Checkmate: Breaking the Memory Wall with Optimal Tensor Rematerialization
“Training Kinetics in 15 Minutes: Large-Scale Distributed Training on Videos ”, Lin et al 2019
Training Kinetics in 15 Minutes: Large-scale Distributed Training on Videos
“Energy and Policy Considerations for Deep Learning in NLP ”, Strubell et al 2019
“Large Batch Optimization for Deep Learning: Training BERT in 76 Minutes ”, You et al 2019
Large Batch Optimization for Deep Learning: Training BERT in 76 minutes
“GAP: Generalizable Approximate Graph Partitioning Framework ”, Nazi et al 2019
“An Empirical Model of Large-Batch Training ”, McCandlish et al 2018
“Bayesian Layers: A Module for Neural Network Uncertainty ”, Tran et al 2018
“GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism ”, Huang et al 2018
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
“Measuring the Effects of Data Parallelism on Neural Network Training ”, Shallue et al 2018
Measuring the Effects of Data Parallelism on Neural Network Training
“Mesh-TensorFlow: Deep Learning for Supercomputers ”, Shazeer et al 2018
“There Is Plenty of Time at the Bottom: the Economics, Risk and Ethics of Time Compression ”, Sandberg 2018
There is plenty of time at the bottom: the economics, risk and ethics of time compression
“Highly Scalable Deep Learning Training System With Mixed-Precision: Training ImageNet in 4 Minutes ”, Jia et al 2018
Highly Scalable Deep Learning Training System with Mixed-Precision: Training ImageNet in 4 Minutes
“AI and Compute ”, Amodei et al 2018
“Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions ”, Vasilache et al 2018
Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions
“Loihi: A Neuromorphic Manycore Processor With On-Chip Learning ”, Davies et al 2018
Loihi: A Neuromorphic Manycore Processor with On-Chip Learning
“Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training ”, Lin et al 2017
Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training
“Mixed Precision Training ”, Micikevicius et al 2017
“On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima ”, Keskar et al 2016
On Large-Batch Training for Deep Learning: Generalization Gap and Sharp Minima
“Training Deep Nets With Sublinear Memory Cost ”, Chen et al 2016
“GeePS: Scalable Deep Learning on Distributed GPUs With a GPU-Specialized Parameter Server ”, Cui et al 2016
GeePS: scalable deep learning on distributed GPUs with a GPU-specialized parameter server
“Convolutional Networks for Fast, Energy-Efficient Neuromorphic Computing ”, Esser et al 2016
Convolutional Networks for Fast, Energy-Efficient Neuromorphic Computing
“Communication-Efficient Learning of Deep Networks from Decentralized Data ”, McMahan et al 2016
Communication-Efficient Learning of Deep Networks from Decentralized Data
“Persistent RNNs: Stashing Recurrent Weights On-Chip ”, Diamos et al 2016
“The Brain As a Universal Learning Machine ”, Cannell 2015
“Scaling Distributed Machine Learning With the Parameter Server ”, Li et al 2014
Scaling Distributed Machine Learning with the Parameter Server
“Multi-Column Deep Neural Network for Traffic Sign Classification ”, Cireşan et al 2012b
Multi-column deep neural network for traffic sign classification
“Multi-Column Deep Neural Networks for Image Classification ”, Cireşan et al 2012
“Building High-Level Features Using Large Scale Unsupervised Learning ”, Le et al 2011
Building high-level features using large scale unsupervised learning
“Implications of Historical Trends in the Electrical Efficiency of Computing ”, Koomey et al 2011
Implications of Historical Trends in the Electrical Efficiency of Computing
“HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent ”, Niu et al 2011
HOGWILD!: A Lock-Free Approach to Parallelizing Stochastic Gradient Descent
“DanNet: Flexible, High Performance Convolutional Neural Networks for Image Classification ”, Ciresan et al 2011
DanNet: Flexible, High Performance Convolutional Neural Networks for Image Classification
“Goodbye 2010 ”, Legg 2010
“Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition ”, Ciresan et al 2010
Deep Big Simple Neural Nets Excel on Handwritten Digit Recognition
“The Cat Is out of the Bag: Cortical Simulations With 109 Neurons, 1013 Synapses ”, Ananthanarayanan et al 2009
The cat is out of the bag: cortical simulations with 109 neurons, 1013 synapses
“Large-Scale Deep Unsupervised Learning Using Graphics Processors ”, Raina et al 2009
Large-scale deep unsupervised learning using graphics processors
“Bandwidth Optimal All-Reduce Algorithms for Clusters of Workstations ”, Patarasuk & Yuan 2009
Bandwidth optimal all-reduce algorithms for clusters of workstations
“Whole Brain Emulation: A Roadmap ”
“Moore’s Law and the Technology S-Curve ”, Bowden 2004
“DARPA and the Quest for Machine Intelligence, 1983–1993 ”, Roland & Shiman 2002
“Ultimate Physical Limits to Computation ”, Lloyd 1999
“Matrioshka Brains ”
“When Will Computer Hardware Match the Human Brain? ”, Moravec 1998
“Superhumanism: According to Hans Moravec § AI Scaling ”, Platt 1995
“A Sociological Study of the Official History of the Perceptrons Controversy [1993] ”, Olazaran 1993
A Sociological Study of the Official History of the Perceptrons Controversy [1993]
“Intelligence As an Emergent Behavior; Or, The Songs of Eden ”, Hillis 1988
Intelligence as an Emergent Behavior; or, The Songs of Eden :
View PDF:
“Computing With Connections ”, Sejnowski 1987
“The Role Of RAW POWER In INTELLIGENCE ”, Moravec 1976
“Brain Performance in FLOPS ”
“Google Demonstrates Leading Performance in Latest MLPerf Benchmarks ”
Google demonstrates leading performance in latest MLPerf Benchmarks :
“H100 GPUs Set Standard for Gen AI in Debut MLPerf Benchmark ”
“Introducing Cerebras Inference: AI at Instant Speed ”, Cerebras 2025
“Llama-3.1-405B Now Runs at 969 Tokens/s on Cerebras Inference ”
Llama-3.1-405B now runs at 969 tokens/s on Cerebras Inference :
“Cerebras Systems Unveils World’s Fastest AI Chip With Whopping 4 Trillion Transistors ”
Cerebras Systems Unveils World’s Fastest AI Chip with Whopping 4 Trillion Transistors :
“Crusoe Expands AI Data Center Campus in Abilene to 1.2 Gigawatts ”
Crusoe Expands AI Data Center Campus in Abilene to 1.2 Gigawatts
“NVIDIA Hopper Architecture In-Depth ”
“AI Progress Is about to Speed Up ”
“Trends in GPU Price-Performance ”
“NVIDIA/Megatron-LM: Ongoing Research Training Transformer Models at Scale ”
NVIDIA/Megatron-LM: Ongoing research training transformer models at scale
“12 Hours Later, Groq Deploys Llama-3-Instruct (8 & 70B) ”
“The Technology Behind BLOOM Training ”
“From Bare Metal to a 70B Model: Infrastructure Set-Up and Scripts ”
From bare metal to a 70B model: infrastructure set-up and scripts
“AI Accelerators, Part IV: The Very Rich Landscape ”, Fuchs 2025
“NVIDIA Announces DGX H100 Systems – World’s Most Advanced Enterprise AI Infrastructure ”
NVIDIA Announces DGX H100 Systems – World’s Most Advanced Enterprise AI Infrastructure
“NVIDIA Launches UK’s Most Powerful Supercomputer, for Research in AI and Healthcare ”
NVIDIA Launches UK’s Most Powerful Supercomputer, for Research in AI and Healthcare
“Perlmutter, Said to Be the World’s Fastest AI Supercomputer, Comes Online ”
Perlmutter, said to be the world’s fastest AI supercomputer, comes online :
“TensorFlow Research Cloud (TRC): Accelerate Your Cutting-Edge Machine Learning Research With Free Cloud TPUs ”, TRC 2025
“Cerebras’ Tech Trains "Brain-Scale" AIs ”
“Fugaku Holds Top Spot, Exascale Remains Elusive ”
“342 Transistors for Every Person In the World: Cerebras 2nd Gen Wafer Scale Engine Teased ”
342 Transistors for Every Person In the World: Cerebras 2nd Gen Wafer Scale Engine Teased :
“Jim Keller Becomes CTO at Tenstorrent: ‘The Most Promising Architecture Out There’ ”
Jim Keller Becomes CTO at Tenstorrent: ‘The Most Promising Architecture Out There’ :
“NVIDIA Unveils Grace: A High-Performance Arm Server CPU For Use In Big AI Systems ”
NVIDIA Unveils Grace: A High-Performance Arm Server CPU For Use In Big AI Systems :
“Cerebras Unveils Wafer Scale Engine Two (WSE2): 2.6 Trillion Transistors, 100% Yield ”
Cerebras Unveils Wafer Scale Engine Two (WSE2): 2.6 Trillion Transistors, 100% Yield :
“AMD Announces Instinct MI200 Accelerator Family: Taking Servers to Exascale and Beyond ”
AMD Announces Instinct MI200 Accelerator Family: Taking Servers to Exascale and Beyond :
“NVIDIA Hopper GPU Architecture and H100 Accelerator Announced: Working Smarter and Harder ”
NVIDIA Hopper GPU Architecture and H100 Accelerator Announced: Working Smarter and Harder :
“Biological Anchors: A Trick That Might Or Might Not Work ”
“Scaling Up and Out: Training Massive Models on Cerebras Systems Using Weight Streaming ”
Scaling Up and Out: Training Massive Models on Cerebras Systems using Weight Streaming :
“DeepSeek: The Quiet Giant Leading China’s AI Race ”
“DeepSeek: The View from China ”
“DeepSeek’s Edge ”
“Fermi Estimate of Future Training Runs ”
“Carl Shulman #2: AI Takeover, Bio & Cyber Attacks, Detecting Deception, & Humanity's Far Future ”
Carl Shulman #2: AI Takeover, Bio & Cyber Attacks, Detecting Deception, & Humanity's Far Future
“Etched Is Making the Biggest Bet in AI ”
“The Emerging Age of AI Diplomacy: To Compete With China, the United States Must Walk a Tightrope in the Gulf ”
“How Far Can AI Progress Before Hitting Effective Physical Limits? ”
How Far Can AI Progress Before Hitting Effective Physical Limits?
“The Resilience Myth: Fatal Flaws in the Push to Secure Chip Supply Chains ”
The resilience myth: fatal flaws in the push to secure chip supply chains :
“Prime Minister Sets out Blueprint to Turbocharge AI ”
“Compute Funds and Pre-Trained Models ”
“The Next Big Thing: Introducing IPU-POD128 and IPU-POD256 ”
“The WoW Factor: Graphcore Systems Get Huge Power and Efficiency Boost ”
The WoW Factor: Graphcore systems get huge power and efficiency boost :
“AWS Enables 4,000-GPU UltraClusters With New P4 A100 Instances ”
AWS Enables 4,000-GPU UltraClusters with New P4 A100 Instances :
“Estimating Training Compute of Deep Learning Models ”
“What O3 Becomes by 2028 ”, Nesov 2025
“The Colliding Exponentials of AI ”
“Moore’s Law, AI, and the pace of Progress ”
“How Fast Can We Perform a Forward Pass? ”
“"AI and Compute" Trend Isn’t Predictive of What Is Happening ”
"AI and Compute" trend isn’t predictive of what is happening :
“Brain Efficiency: Much More Than You Wanted to Know ”
“DeepSpeed: Accelerating Large-Scale Model Inference and Training via System Optimizations and Compression ”
“ZeRO-Infinity and DeepSpeed: Unlocking Unprecedented Model Scale for Deep Learning Training ”
ZeRO-Infinity and DeepSpeed: Unlocking unprecedented model scale for deep learning training :
“The World’s Largest Computer Chip ”
“The Billion Dollar AI Problem That Just Keeps Scaling ”
“TSMC Confirms 3nm Tech for 2022, Could Enable Epic 80 Billion Transistor GPUs ”
TSMC confirms 3nm tech for 2022, could enable epic 80 billion transistor GPUs :
“ORNL’s Frontier First to Break the Exaflop Ceiling ”
“A Spymaster Sheikh Controls a $1.5 Trillion Fortune. Tahnoun Bin Zayed Al Nahyan Wants to Use It to Dominate AI ”
“Returning to Google DeepMind ”, Tay 2025
“How to Accelerate Innovation With AI at Scale ”
“48:44—Tesla Vision • 1:13:12—Planning and Control • 1:24:35—Manual Labeling • 1:28:11—Auto Labeling • 1:35:15—Simulation • 1:42:10—Hardware Integration • 1:45:40—Dojo ”
ID_AA_Carmack
lepikhin
Wikipedia (16)
Miscellaneous
/doc/ai/scaling/mixture-of-experts/2021-04-12-jensenhuang-gtc2021keynote-ean_oizwuxa.en.vtt.txt:/doc/ai/scaling/hardware/2021-jouppi-table1-keycharacteristicsoftpus.png:/doc/ai/scaling/hardware/2021-ren-zerooffload-cpugpudataflow.png:/doc/ai/scaling/hardware/2020-08-05-hippke-measuringhardwareoverhang-chessscaling19902020.png:/doc/ai/scaling/hardware/2020-kumar-figure11-tpumultipodspeedups.png:/doc/ai/scaling/hardware/2017-jouppi.pdf:View PDF:
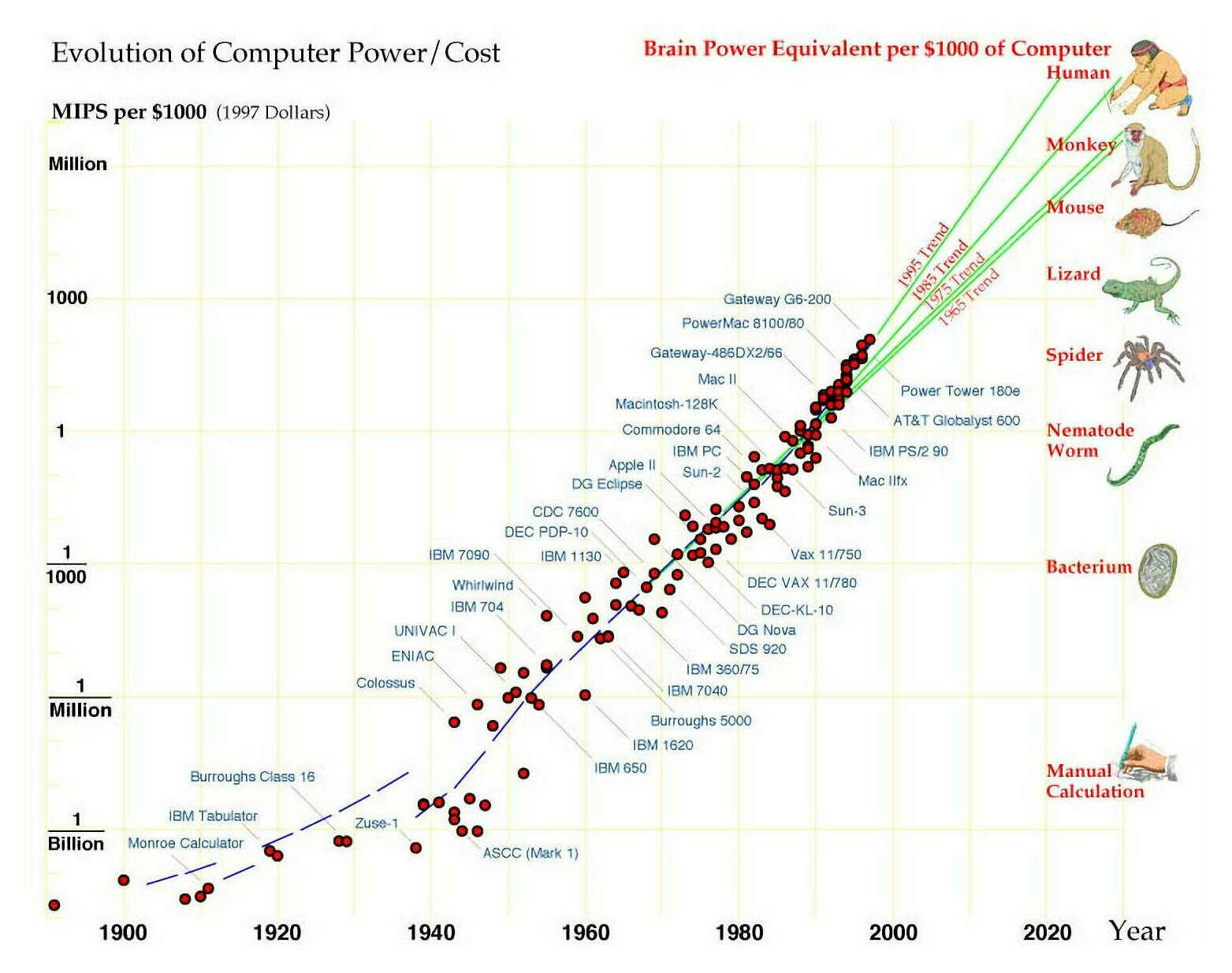
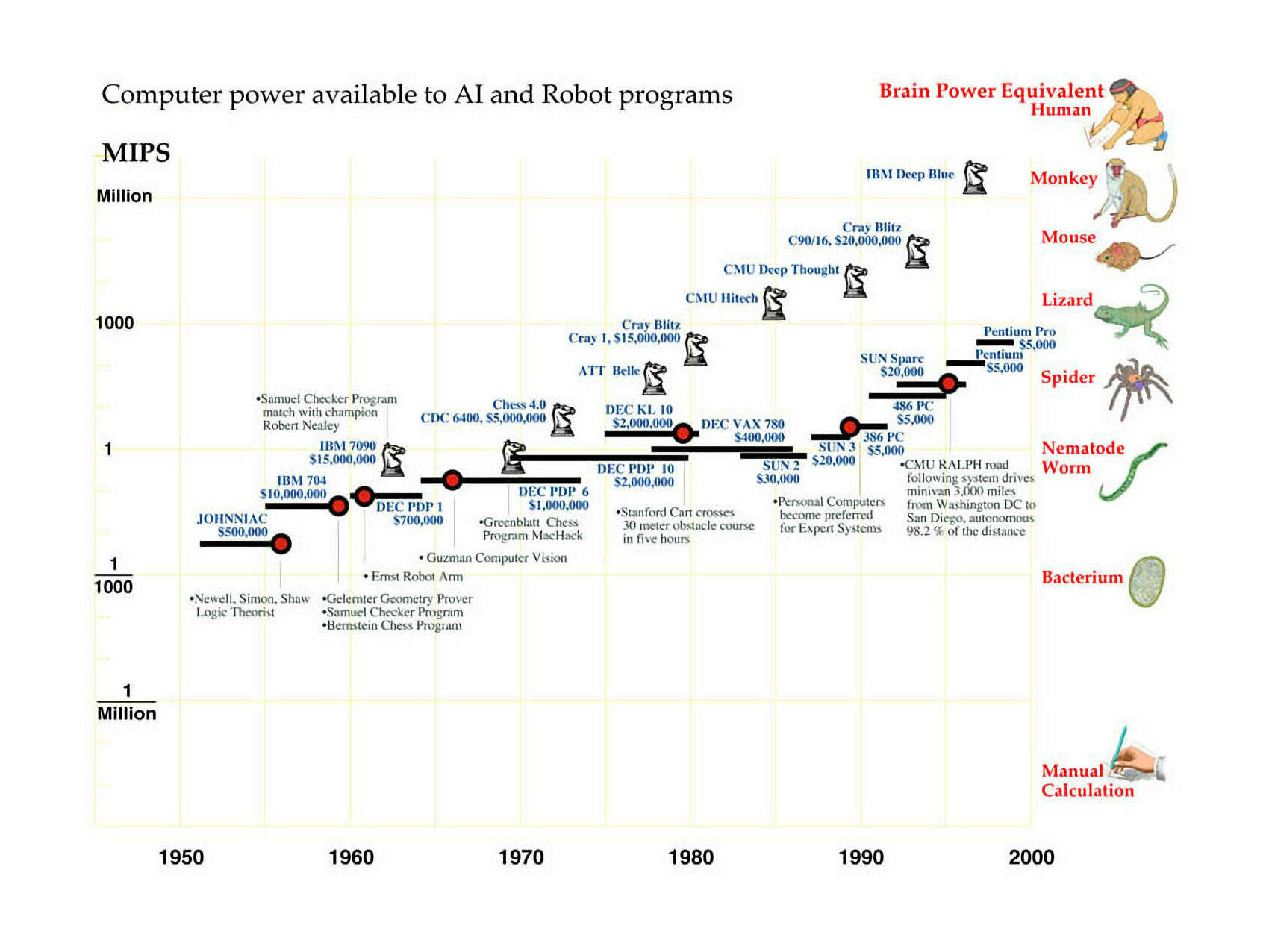
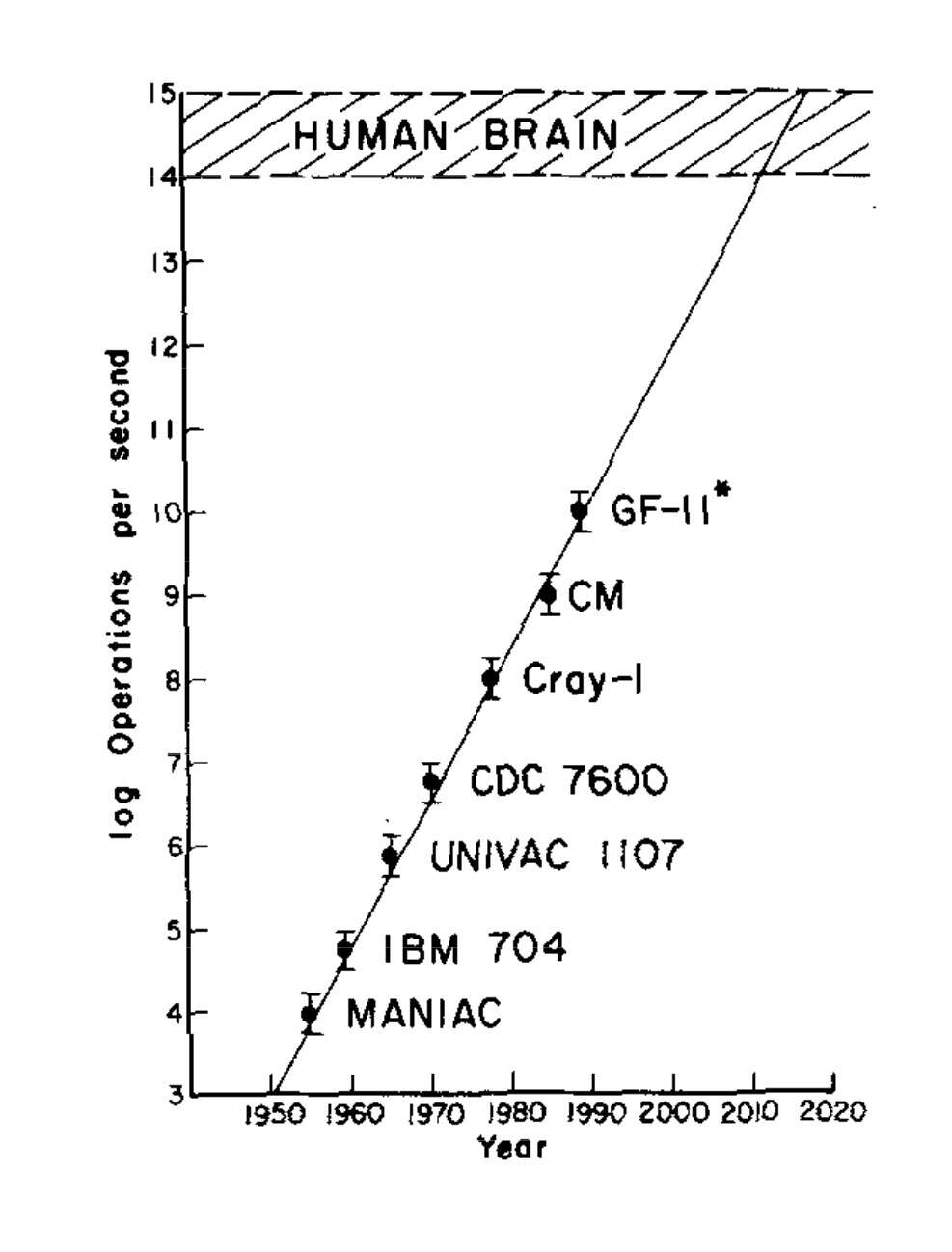
/doc/ai/scaling/hardware/1998-moravec-figure2-evolutionofcomputerpowercost19001998.csv:/doc/ai/scaling/hardware/1998-moravec-figure2-evolutionofcomputerpowercost19001998.jpg:/doc/ai/scaling/hardware/1998-moravec-figure3-peakcomputeuseinai19501998.jpg:https://ai.meta.com/blog/meta-training-inference-accelerator-AI-MTIA/https://ai.meta.com/blog/next-generation-meta-training-inference-accelerator-AI-MTIA/:https://blogs.nvidia.com/blog/2021/04/12/cpu-grace-cscs-alps/https://blogs.nvidia.com/blog/2022/09/08/hopper-mlperf-inference/https://caseyhandmer.wordpress.com/2024/03/12/how-to-feed-the-ais/:https://chipsandcheese.com/2023/07/02/nvidias-h100-funny-l2-and-tons-of-bandwidth/https://cloud.google.com/blog/topics/systems/the-evolution-of-googles-jupiter-data-center-networkhttps://evabehrens.substack.com/p/the-agi-race-between-the-us-and-chinahttps://gpus.llm-utils.org/nvidia-h100-gpus-supply-and-demand/:https://gpus.llm-utils.org/nvidia-h100-gpus-supply-and-demand/#how-do-the-big-clouds-compare:https://newsletter.pragmaticengineer.com/p/scaling-chatgpt#%C2%A7five-scaling-challenges:https://openai.com/blog/techniques-for-training-large-neural-networks/https://openai.com/research/scaling-kubernetes-to-7500-nodeshttps://research.google/blog/tensorstore-for-high-performance-scalable-array-storage/https://spectrum.ieee.org/computing/hardware/the-future-of-deep-learning-is-photonic:https://thechipletter.substack.com/p/googles-first-tpu-architecturehttps://venturebeat.com/2020/11/17/cerebras-wafer-size-chip-is-10000-times-faster-than-a-gpu/:https://warontherocks.com/2024/04/how-washington-can-save-its-semiconductor-controls-on-china/:https://www.abortretry.fail/p/the-rise-and-fall-of-silicon-graphics:https://www.cerebras.net/blog/introducing-gigagpt-gpt-3-sized-models-in-565-lines-of-code:https://www.cerebras.net/press-release/cerebras-announces-third-generation-wafer-scale-engine:https://www.chinatalk.media/p/new-chip-export-controls-explained:https://www.chinatalk.media/p/new-sexport-controls-semianalysishttps://www.ft.com/content/25337df3-5b98-4dd1-b7a9-035dcc130d6a:https://www.fujitsu.com/global/about/resources/news/press-releases/2024/0510-01.html:https://www.lesswrong.com/posts/YKfNZAmiLdepDngwi/gpt-175beehttps://www.nytimes.com/2022/10/13/us/politics/biden-china-technology-semiconductors.htmlhttps://www.nytimes.com/2023/07/12/magazine/semiconductor-chips-us-china.htmlhttps://www.reddit.com/r/MachineLearning/comments/1dlsogx/d_academic_ml_labs_how_many_gpus/:https://www.reuters.com/technology/inside-metas-scramble-catch-up-ai-2023-04-25/https://www.theregister.com/2023/11/07/bing_gpu_oracle/:View External Link:
https://www.yitay.net/blog/training-great-llms-entirely-from-ground-zero-in-the-wilderness
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Bibliography
https://www.reuters.com/technology/artificial-intelligence/alphabet-nvidia-invest-openai-co-founder-sutskevers-ssi-source-says-2025-04-12/: “Alphabet, Nvidia Invest in OpenAI Co-Founder Sutskever’s SSI, Source Says ”,https://benjamintodd.substack.com/p/why-a-us-ai-manhattan-project-could: “Why a US AI "Manhattan Project" Could Backfire: Notes from Conversations in China ”,https://www.theatlantic.com/international/archive/2024/06/china-microchip-technology-competition/678612/: “China Is Losing the Chip War: Xi Jinping Picked a Fight over Semiconductor Technology—One He Can’t Win ”,https://www.ft.com/content/8e8a65a0-a990-4c77-a6e8-ec4e5d247f80: “Singapore’s Temasek in Discussions to Invest in OpenAI: State-Backed Group in Talks With ChatGPT Maker’s Chief Sam Altman Who Is Seeking Funding to Build Chips Business ”,https://www.newyorker.com/magazine/2023/12/04/how-jensen-huangs-nvidia-is-powering-the-ai-revolution: “How Jensen Huang’s Nvidia Is Powering the AI Revolution: The Company’s CEO Bet It All on a New Kind of Chip. Now That Nvidia Is One of the Biggest Companies in the World, What Will He Do Next? ”,https://www.wired.com/story/openai-buy-ai-chips-startup-sam-altman/: “OpenAI Agreed to Buy $51 Million of AI Chips From a Startup Backed by CEO Sam Altman ”,https://www.semianalysis.com/p/microsoft-swallows-openais-core-team#%C2%A7compute-is-king: “Microsoft Swallows OpenAI’s Core Team § Compute Is King ”,https://www.ft.com/content/2a636cee-b0d2-45c2-a815-11ca32371763: “Saudi-China Collaboration Raises Concerns about Access to AI Chips: Fears Grow at Gulf Kingdom’s Top University That Ties to Chinese Researchers Risk Upsetting US Government ”,https://www.nytimes.com/2023/07/16/opinion/biden-china-ai-chips-trade.html: “Biden Is Beating China on Chips. It May Not Be Enough. ”,https://www.wsj.com/articles/the-ai-boom-runs-on-chips-but-it-cant-get-enough-9f76f554: “The AI Boom Runs on Chips, but It Can’t Get Enough: ‘It’s like Toilet Paper during the Pandemic.’ Startups, Investors Scrounge for Computational Firepower ”,https://arxiv.org/abs/2305.06946: “Big-PERCIVAL: Exploring the Native Use of 64-Bit Posit Arithmetic in Scientific Computing ”,https://x.com/davidtayar5/status/1627690520456691712: “Context on the NVIDIA ChatGPT Opportunity—And Ramifications of Large Language Model Enthusiasm ”,https://blogs.microsoft.com/blog/2023/01/23/microsoftandopenaiextendpartnership/: “Microsoft and OpenAI Extend Partnership ”,https://ai.meta.com/blog/multiray-large-scale-AI-models/: “MultiRay: Optimizing Efficiency for Large-Scale AI Models ”,https://arxiv.org/abs/2211.05102#google: “Efficiently Scaling Transformer Inference ”,https://arxiv.org/abs/2206.03382#microsoft: “Tutel: Adaptive Mixture-Of-Experts at Scale ”,https://arxiv.org/abs/2206.01861#microsoft: “ZeroQuant: Efficient and Affordable Post-Training Quantization for Large-Scale Transformers ”,https://arxiv.org/abs/2205.14135: “FlashAttention: Fast and Memory-Efficient Exact Attention With IO-Awareness ”,https://arxiv.org/abs/2204.00595: “Monarch: Expressive Structured Matrices for Efficient and Accurate Training ”,https://arxiv.org/abs/2203.02094#microsoft: “LiteTransformerSearch: Training-Free Neural Architecture Search for Efficient Language Models ”,https://arxiv.org/abs/2202.06009#microsoft: “Maximizing Communication Efficiency for Large-Scale Training via 0/1 Adam ”,https://ai.meta.com/blog/ai-rsc/: “Introducing the AI Research SuperCluster—Facebook’s Cutting-Edge AI Supercomputer for AI Research ”,https://semiengineering.com/is-programmable-overhead-worth-the-cost/: “Is Programmable Overhead Worth The Cost? How Much Do We Pay for a System to Be Programmable? It Depends upon Who You Ask ”,https://arxiv.org/abs/2106.10207: “Distributed Deep Learning in Open Collaborations ”,2021-jouppi.pdf: “Ten Lessons From Three Generations Shaped Google’s TPUv4i ”,https://chinai.substack.com/p/chinai-141-the-pangu-origin-story: “ChinAI #141: The PanGu Origin Story: Notes from an Informative Zhihu Thread on PanGu ”,https://arxiv.org/abs/2104.06272#deepmind: “Podracer Architectures for Scalable Reinforcement Learning ”,https://arxiv.org/abs/2104.05343: “An Efficient 2D Method for Training Super-Large Deep Learning Models ”,https://arxiv.org/abs/2102.07988: “TeraPipe: Token-Level Pipeline Parallelism for Training Large-Scale Language Models ”,https://arxiv.org/abs/2102.03161: “PipeTransformer: Automated Elastic Pipelining for Distributed Training of Transformers ”,2020-jiang.pdf: “BytePS: A Unified Architecture for Accelerating Distributed DNN Training in Heterogeneous GPU/CPU Clusters ”,https://arxiv.org/abs/2011.00071#google: “Training EfficientNets at Supercomputer Scale: 83% ImageNet Top-1 Accuracy in One Hour ”,2020-launay-2.pdf: “Direct Feedback Alignment Scales to Modern Deep Learning Tasks and Architectures ”,https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/: “DeepSpeed: Extreme-Scale Model Training for Everyone ”,https://news.microsoft.com/source/features/ai/openai-azure-supercomputer/: “Microsoft Announces New Supercomputer, Lays out Vision for Future AI Work ”,https://www.zdnet.com/article/startup-tenstorrent-and-competitors-show-how-computing-is-changing-ai-and-vice-versa/: “Startup Tenstorrent Shows AI Is Changing Computing and vice Versa: Tenstorrent Is One of the Rush of AI Chip Makers Founded in 2016 and Finally Showing Product. The New Wave of Chips Represent a Substantial Departure from How Traditional Computer Chips Work, but Also Point to Ways That Neural Network Design May Change in the Years to Come ”,2020-khan.pdf: “AI Chips: What They Are and Why They Matter—An AI Chips Reference ”,https://arxiv.org/abs/1904.00962#google: “Large Batch Optimization for Deep Learning: Training BERT in 76 Minutes ”,https://arxiv.org/abs/1811.06965#google: “GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism ”,https://arxiv.org/abs/1811.02084#google: “Mesh-TensorFlow: Deep Learning for Supercomputers ”,https://openai.com/research/ai-and-compute: “AI and Compute ”,https://arxiv.org/abs/1712.01887: “Deep Gradient Compression: Reducing the Communication Bandwidth for Distributed Training ”,https://arxiv.org/abs/1102.0183#schmidhuber: “DanNet: Flexible, High Performance Convolutional Neural Networks for Image Classification ”,https://www.vetta.org/2010/12/goodbye-2010/: “Goodbye 2010 ”,2009-raina.pdf: “Large-Scale Deep Unsupervised Learning Using Graphics Processors ”,2009-patarasuk.pdf: “Bandwidth Optimal All-Reduce Algorithms for Clusters of Workstations ”,https://www.wired.com/1995/10/moravec/#scaling: “Superhumanism: According to Hans Moravec § AI Scaling ”,1993-olazaran.pdf: “A Sociological Study of the Official History of the Perceptrons Controversy [1993] ”,1987-sejnowski.pdf: “Computing With Connections ”,https://web.archive.org/web/20230710000944/https://frc.ri.cmu.edu/~hpm/project.archive/general.articles/1975/Raw.Power.html: “The Role Of RAW POWER In INTELLIGENCE ”,https://sites.research.google/trc/: “TensorFlow Research Cloud (TRC): Accelerate Your Cutting-Edge Machine Learning Research With Free Cloud TPUs ”,