‘model-free RL’ directory
- See Also
- Gwern
- Links
- “Interpreting Emergent Planning in Model-Free Reinforcement Learning ”, Bush et al 2025
- “2024 Turing Award: Andrew Barto & Richard Sutton ”, ACM 2025
- “Training Language Models for Social Deduction With Multi-Agent Reinforcement Learning ”, Sarkar et al 2025
- “Value-Based Deep RL Scales Predictably ”, Rybkin et al 2025
- “MR.Q: Towards General-Purpose Model-Free Reinforcement Learning ”, Fujimoto et al 2025
- “Amplifying Human Performance in Combinatorial Competitive Programming ”, Veličković et al 2024
- “Deep Reinforcement Learning Without Experience Replay, Target Networks, or Batch Updates ”, Elsayed et al 2024
- “Centaur: a Foundation Model of Human Cognition ”, Binz et al 2024
- “SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning ”, Lee et al 2024
- “Training Language Models to Self-Correct via Reinforcement Learning ”, Kumar et al 2024
- “Carpentopod: A Walking Table Project ”, Carpentier 2024
- “Mind Wandering During Implicit Learning Is Associated With Increased Periodic EEG Activity And Improved Extraction Of Hidden Probabilistic Patterns ”, Simor et al 2024
- “Alexa Is in Millions of Households—And Amazon Is Losing Billions ”, Mattioli 2024
- “Bigger, Regularized, Optimistic: Scaling for Compute and Sample-Efficient Continuous Control ”, Nauman et al 2024
- “Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo ”, Zhao et al 2024
- “Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data ”, Tajwar et al 2024
- “Automatic Design of Stigmergy-Based Behaviors for Robot Swarms ”, Salman et al 2024
- “CodeIt: Self-Improving Language Models With Prioritized Hindsight Replay ”, Butt et al 2024
- “ReST Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent ”, Aksitov et al 2023
- “Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning ”, Dutta et al 2023
- “Let Models Speak Ciphers: Multiagent Debate through Embeddings ”, Pham et al 2023
- “Predictive Auxiliary Objectives in Deep RL Mimic Learning in the Brain ”, Fang & Stachenfeld 2023
- “Small Batch Deep Reinforcement Learning ”, Obando-Ceron et al 2023
- “Maximum Diffusion Reinforcement Learning ”, Berrueta et al 2023
- “Subwords As Skills: Tokenization for Sparse-Reward Reinforcement Learning ”, Yunis et al 2023
- “Comparative Study of Model-Based and Model-Free Reinforcement Learning Control Performance in HVAC Systems ”, Gao & Wang 2023
- “What Are Dreams For? Converging Lines of Research Suggest That We Might Be Misunderstanding Something We Do Every Night of Our Lives ”, Gefter 2023
- “Learning to Model the World With Language ”, Lin et al 2023
- “Low-Poly Image Generation Using Evolutionary Algorithms in Ruby ”
- “Parallel Q-Learning (PQL): Scaling Off-Policy Reinforcement Learning under Massively Parallel Simulation ”, Li et al 2023
- “Using Temperature to Analyze the Neural Basis of a Time-Based Decision ”, Monteiro et al 2023
- “Minigrid & Miniworld: Modular & Customizable Reinforcement Learning Environments for Goal-Oriented Tasks ”, Chevalier-Boisvert et al 2023
- “Twitching in Sensorimotor Development from Sleeping Rats to Robots ”, Blumberg et al 2023
- “Universal Mechanical Polycomputation in Granular Matter ”, Parsa et al 2023
- “Lucy-SKG: Learning to Play Rocket League Efficiently Using Deep Reinforcement Learning ”, Moschopoulos et al 2023
- “Improving Language Models With Advantage-Based Offline Policy Gradients ”, Baheti et al 2023
- “Micromouse: The Fastest Maze-Solving Competition On Earth ”, Veritasium 2023
- “Reinforcement Learning in Newcomb-Like Environments ”, Bell et al 2023
- “WizardLM: Empowering Large Language Models to Follow Complex Instructions ”, Xu et al 2023
- “Bridging Discrete and Backpropagation: Straight-Through and Beyond ”, Liu et al 2023
- “Empirical Design in Reinforcement Learning ”, Patterson et al 2023
- “A Circuit Mechanism Linking past and Future Learning through Shifts in Perception ”, Crossley et al 2023
- “Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier ”, D’Oro et al 2023
- “Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula ”, Bronstein et al 2022
- “Melting Pot 2.0 ”, Agapiou et al 2022
- “Token Turing Machines ”, Ryoo et al 2022
- “Legged Locomotion in Challenging Terrains Using Egocentric Vision ”, Agarwal et al 2022
- “Over-Communicate No More: Situated RL Agents Learn Concise Communication Protocols ”, Kalinowska et al 2022
- “E3B: Exploration via Elliptical Episodic Bonuses ”, Henaff et al 2022
- “Hyperbolic Deep Reinforcement Learning ”, Cetin et al 2022
- “Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization ”, Ramamurthy et al 2022
- “Dynamic Prompt Learning via Policy Gradient for Semi-Structured Mathematical Reasoning ”, Lu et al 2022
- “Simplifying Model-Based RL: Learning Representations, Latent-Space Models, and Policies With One Objective (ALM) ”, Ghugare et al 2022
- “Human-Level Atari 200× Faster ”, Kapturowski et al 2022
- “Nearest Neighbor Non-Autoregressive Text Generation ”, Niwa et al 2022
- “A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning ”, Dann et al 2022
- “Learning to Generalize With Object-Centric Agents in the Open World Survival Game Crafter ”, Stanić et al 2022
- “Improved Policy Optimization for Online Imitation Learning ”, Lavington et al 2022
- “Offline RL for Natural Language Generation With Implicit Language Q Learning ”, Snell et al 2022
- “Fine-Grained Image Captioning With CLIP Reward ”, Cho et al 2022
- “Reward Bases: Instantaneous Reward Revaluation With Temporal Difference Learning ”, Millidge et al 2022
- “Is Vanilla Policy Gradient Overlooked? Analyzing Deep Reinforcement Learning for Hanabi ”, Grooten et al 2022
- “Quantifying and Alleviating Political Bias in Language Models ”, Liu et al 2022c
- “Machine Learning Helps Control Tokamak Plasmas ”, Georgescu 2022
- “Retrieval-Augmented Reinforcement Learning ”, Goyal et al 2022
- “Policy Learning and Evaluation With Randomized Quasi-Monte Carlo ”, Arnold et al 2022
- “A Data-Driven Approach for Learning to Control Computers ”, Humphreys et al 2022
- “Magnetic Control of Tokamak Plasmas through Deep Reinforcement Learning ”, Degrave et al 2022
- “Why Should I Trust You, Bellman? The Bellman Error Is a Poor Replacement for Value Error ”, Fujimoto et al 2022
- “Learning Dynamics and Generalization in Deep Reinforcement Learning ”, Lyle et al 2022
- “Agile Locomotion via Model-Free Learning ”, Margolis 2022
- “Amortized Noisy Channel Neural Machine Translation ”, Pang et al 2021
- “Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs ”, Korkmaz 2021
- “Residual Pathway Priors for Soft Equivariance Constraints ”, Finzi et al 2021
- “Simple but Effective: CLIP Embeddings for Embodied AI ”, Khandelwal et al 2021
- “Offline Reinforcement Learning With Implicit Q-Learning (IQL) ”, Kostrikov et al 2021
- “Recurrent Model-Free RL Is a Strong Baseline for Many POMDPs ”, Ni et al 2021
- “DroQ: Dropout Q-Functions for Doubly Efficient Reinforcement Learning ”, Hiraoka et al 2021
- “Batch Size-Invariance for Policy Optimization ”, Hilton et al 2021
- “MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research ”, Samvelyan et al 2021
- “Bootstrapped Meta-Learning ”, Flennerhag et al 2021
- “Megaverse: Simulating Embodied Agents at One Million Experiences per Second ”, Petrenko et al 2021
- “PES: Unbiased Gradient Estimation in Unrolled Computation Graphs With Persistent Evolution Strategies ”, Vicol et al 2021
- “Multi-Task Curriculum Learning in a Complex, Visual, Hard-Exploration Domain: Minecraft ”, Kanitscheider et al 2021
- “On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning ”, Vischer et al 2021
- “Constructions in Combinatorics via Neural Networks ”, Wagner 2021
- “Muesli: Combining Improvements in Policy Optimization ”, Hessel et al 2021
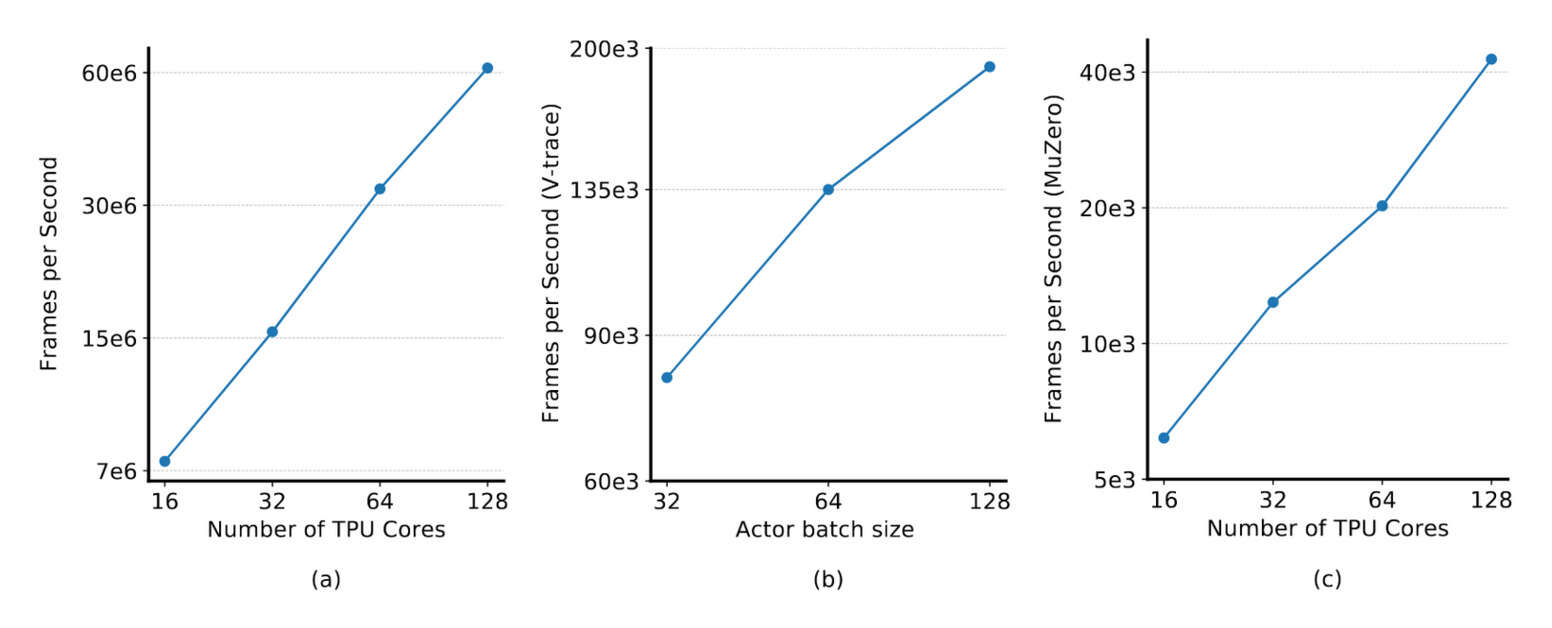
- “Podracer Architectures for Scalable Reinforcement Learning ”, Hessel et al 2021
- “Counter-Strike Deathmatch With Large-Scale Behavioral Cloning ”, Pearce & Zhu 2021
- “ALD: Efficient Transformers in Reinforcement Learning Using Actor-Learner Distillation ”, Parisotto & Salakhutdinov 2021
- “Replay in Deep Learning: Current Approaches and Missing Biological Elements ”, Hayes et al 2021
- “Large Batch Simulation for Deep Reinforcement Learning ”, Shacklett et al 2021
- “The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games ”, Yu et al 2021
- “Reinforcement Learning for Datacenter Congestion Control ”, Tessler et al 2021
- “Training Larger Networks for Deep Reinforcement Learning ”, Ota et al 2021
- “How RL Agents Behave When Their Actions Are Modified ”, Langlois & Everitt 2021
- “A✱ Search Without Expansions: Learning Heuristic Functions With Deep Q-Networks ”, Agostinelli et al 2021
- “Randomized Ensembled Double Q-Learning (REDQ): Learning Fast Without a Model ”, Chen et al 2021
- “MLGO: a Machine Learning Guided Compiler Optimizations Framework ”, Trofin et al 2021
- “Evolving Reinforcement Learning Algorithms ”, Co-Reyes et al 2021
- “Using Deep Reinforcement Learning to Reveal How the Brain Encodes Abstract State-Space Representations in High-Dimensional Environments ”, Cross 2020
- “Autonomous Navigation of Stratospheric Balloons Using Reinforcement Learning ”, Bellemare et al 2020
- “A Unified Framework for Dopamine Signals across Timescales ”, Kim et al 2020
- “Offline Learning from Demonstrations and Unlabeled Experience ”, Zolna et al 2020
- “Adversarial Vulnerabilities of Human Decision-Making ”, Dezfouli et al 2020
- “D2RL: Deep Dense Architectures in Reinforcement Learning ”, Sinha et al 2020
- “Human-Centric Dialog Training via Offline Reinforcement Learning ”, Jaques et al 2020
- “Emergent Social Learning via Multi-Agent Reinforcement Learning ”, Ndousse et al 2020
- “Super-Human Performance in Gran Turismo Sport Using Deep Reinforcement Learning ”, Fuchs et al 2020
- “SPR: Data-Efficient Reinforcement Learning With Self-Predictive Representations ”, Schwarzer et al 2020
- “Learning Breakout From RAM—Part 2 ”, philoxenic 2020
- “Learning Breakout From RAM—Part 1 ”, philoxenic 2020
- “Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks ”, Papoudakis et al 2020
- “Improving GAN Training With Probability Ratio Clipping and Sample Reweighting ”, Wu et al 2020
- “Conservative Q-Learning for Offline Reinforcement Learning ”, Kumar et al 2020
- “Controlling Overestimation Bias With Truncated Mixture of Continuous Distributional Quantile Critics (TQC) ”, Kuznetsov et al 2020
- “Evaluating the Rainbow DQN Agent in Hanabi With Unseen Partners ”, Canaan et al 2020
- “Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels ”, Kostrikov et al 2020
- “Chip Placement With Deep Reinforcement Learning ”, Mirhoseini et al 2020
- “CURL: Contrastive Unsupervised Representations for Reinforcement Learning ”, Srinivas et al 2020
- “Evolving Normalization-Activation Layers ”, Liu et al 2020
- “Benchmarking End-To-End Behavioral Cloning on Video Games ”, Kanervisto et al 2020
- “Agent57: Outperforming the Atari Human Benchmark ”, Badia et al 2020
- “Deep Neuroethology of a Virtual Rodent ”, Merel et al 2020
- “Q✱ Approximation Schemes for Batch Reinforcement Learning: A Theoretical Comparison ”, Xie & Jiang 2020
- “Can Increasing Input Dimensionality Improve Deep Reinforcement Learning? ”, Ota et al 2020
- “Causal Evidence Supporting the Proposal That Dopamine Transients Function As Temporal Difference Prediction Errors ”, Maes et al 2020
- “A Distributional Code for Value in Dopamine-Based Reinforcement Learning ”, Dabney et al 2020
- “Combining Q-Learning and Search With Amortized Value Estimates ”, Hamrick et al 2019
- “SEED RL: Scalable and Efficient Deep-RL With Accelerated Central Inference ”, Espeholt et al 2019
- “Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning? ”, Du et al 2019
- “QUARL: Quantized Reinforcement Learning (ActorQ) ”, Lam et al 2019
- “Deep Learning Enables Rapid Identification of Potent DDR1 Kinase Inhibitors ”, Zhavoronkov et al 2019
- “Exponential Slowdown for Larger Populations: The (μ+1)-EA on Monotone Functions ”, Lengler & Zou 2019
- “Is Deep Reinforcement Learning Really Superhuman on Atari? Leveling the Playing Field ”, Toromanoff et al 2019
- “A View on Deep Reinforcement Learning in System Optimization ”, Haj-Ali et al 2019
- “Playing the Lottery With Rewards and Multiple Languages: Lottery Tickets in RL and NLP ”, Yu et al 2019
- “A General Dichotomy of Evolutionary Algorithms on Monotone Functions ”, Lengler 2019
- “A Recipe for Training Neural Networks ”, Karpathy 2019
- “Universal Quantum Control through Deep Reinforcement Learning ”, Niu et al 2019
- “Reinforcement Learning for Recommender Systems: A Case Study on Youtube ”, Chen 2019
- “Benchmarking Classic and Learned Navigation in Complex 3D Environments ”, Mishkin et al 2019
- “AutoPhase: Compiler Phase-Ordering for High Level Synthesis With Deep Reinforcement Learning ”, Haj-Ali et al 2019
- “DRC: An Investigation of Model-Free Planning ”, Guez et al 2019
- “Anxiety, Depression, and Decision Making: A Computational Perspective ”, Bishop & Gagne 2019
- “Reinforcement Learning in Artificial and Biological Systems ”, Neftci & Averbeck 2019
- “Designing Neural Networks through Neuroevolution ”, Stanley et al 2019
- “The Credit Assignment Problem ”, Demski 2019
- “IRLAS: Inverse Reinforcement Learning for Architecture Search ”, Guo et al 2018
- “Quantifying Generalization in Reinforcement Learning ”, Cobbe et al 2018
- “Top-K Off-Policy Correction for a REINFORCE Recommender System ”, Chen et al 2018
- “Relative Entropy Regularized Policy Iteration ”, Abdolmaleki et al 2018
- “ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware ”, Cai et al 2018
- “Neural Probabilistic Motor Primitives for Humanoid Control ”, Merel et al 2018
- “InstaNAS: Instance-Aware Neural Architecture Search ”, Cheng et al 2018
- “A Closer Look at Deep Policy Gradients ”, Ilyas et al 2018
- “One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets With RL ”, Paine et al 2018
- “Reinforcement Learning for Improving Agent Design ”, Ha 2018
- “Reinforcement Learning for Improving Agent Design [Homepage] ”, Ha 2018
- “Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow ”, Peng et al 2018
- “Learning to Perform Local Rewriting for Combinatorial Optimization ”, Chen & Tian 2018
- “R2D2: Recurrent Experience Replay in Distributed Reinforcement Learning ”, Kapturowski et al 2018
- “Benchmarking Reinforcement Learning Algorithms on Real-World Robots ”, Mahmood et al 2018
- “Deterministic Implementations for Reproducibility in Deep Reinforcement Learning ”, Nagarajan et al 2018
- “Multi-Task Deep Reinforcement Learning With PopArt ”, Hessel et al 2018
- “Accelerated Reinforcement Learning for Sentence Generation by Vocabulary Prediction ”, Hashimoto & Tsuruoka 2018
- “Searching Toward Pareto-Optimal Device-Aware Neural Architectures ”, Cheng et al 2018
- “A Study of Reinforcement Learning for Neural Machine Translation ”, Wu et al 2018
- “Improving Abstraction in Text Summarization ”, Kryściński et al 2018
- “Learning to Optimize Join Queries With Deep Reinforcement Learning ”, Krishnan et al 2018
- “InfoNCE: Representation Learning With Contrastive Predictive Coding (CPC) ”, Oord et al 2018
- “Is Q-Learning Provably Efficient? ”, Jin et al 2018
- “Maximum a Posteriori Policy Optimization ”, Abdolmaleki et al 2018
- “The Unusual Effectiveness of Averaging in GAN Training ”, Yazıcı et al 2018
- “Resource-Efficient Neural Architect ”, Zhou et al 2018
- “DVRL: Deep Variational Reinforcement Learning for POMDPs ”, Igl et al 2018
- “Playing Atari With Six Neurons ”, Cuccu et al 2018
- “Measuring the Intrinsic Dimension of Objective Landscapes ”, Li et al 2018
- “DP4G: Distributed Distributional Deterministic Policy Gradients ”, Barth-Maron et al 2018
- “Optimizing Query Evaluations Using Reinforcement Learning for Web Search ”, Rosset et al 2018
- “Simple Random Search Provides a Competitive Approach to Reinforcement Learning ”, Mania et al 2018
- “Delayed Impact of Fair Machine Learning ”, Liu et al 2018
- “Accelerated Methods for Deep Reinforcement Learning ”, Stooke & Abbeel 2018
- “Learning Memory Access Patterns ”, Hashemi et al 2018
- “Investigating Human Priors for Playing Video Game ”, Dubey et al 2018
- “ME-TRPO: Model-Ensemble Trust-Region Policy Optimization ”, Kurutach et al 2018
- “TD3: Addressing Function Approximation Error in Actor-Critic Methods ”, Fujimoto et al 2018
- “Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration ”, Liu et al 2018
- “Unicorn: Continual Learning With a Universal, Off-Policy Agent ”, Mankowitz et al 2018
- “ENAS: Efficient Neural Architecture Search via Parameter Sharing ”, Pham et al 2018
- “Regularized Evolution for Image Classifier Architecture Search ”, Real et al 2018
- “IMPALA: Scalable Distributed Deep-RL With Importance Weighted Actor-Learner Architectures ”, Espeholt et al 2018
- “Interactive Grounded Language Acquisition and Generalization in a 2D World ”, Yu et al 2018
- “Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning With a Stochastic Actor ”, Haarnoja et al 2018
- “Chapter 5: Monte Carlo Methods ”, Sutton & Barto 2018 (page 133)
- “Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning ”, Such et al 2017
- “The Case for Learned Index Structures ”, Kraska et al 2017
- “AI Safety Gridworlds ”, Leike et al 2017
- “Classification With Costly Features Using Deep Reinforcement Learning ”, Janisch et al 2017
- “Reinforcement Learning of Speech Recognition System Based on Policy Gradient and Hypothesis Selection ”, Kato & Shinozaki 2017
- “Towards the Use of Deep Reinforcement Learning With Global Policy For Query-Based Extractive Summarization ”, Molla 2017
- “Swish: Searching for Activation Functions ”, Ramachandran et al 2017
- “Gradient-Free Policy Architecture Search and Adaptation ”, Ebrahimi et al 2017
- “Rainbow: Combining Improvements in Deep Reinforcement Learning ”, Hessel et al 2017
- “OptionGAN: Learning Joint Reward-Policy Options Using Generative Adversarial Inverse Reinforcement Learning ”, Henderson et al 2017
- “Deep Reinforcement Learning That Matters ”, Henderson et al 2017
- “Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents ”, Machado et al 2017
- “Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning ”, Zhong et al 2017
- “The Successor Representation in Human Reinforcement Learning ”, Momennejad et al 2017
- “Practical Block-Wise Neural Network Architecture Generation ”, Zhong et al 2017
- “Learning Policies for Adaptive Tracking With Deep Feature Cascades ”, Huang et al 2017
- “Reinforced Video Captioning With Entailment Rewards ”, Pasunuru & Bansal 2017
- “A Distributional Perspective on Reinforcement Learning ”, Bellemare et al 2017
- “Tracking As Online Decision-Making: Learning a Policy from Streaming Videos With Reinforcement Learning ”, III & Ramanan 2017
- “Trial without Error: Towards Safe Reinforcement Learning via Human Intervention ”, Saunders et al 2017
- “Efficient Architecture Search by Network Transformation ”, Cai et al 2017
- “Grammatical Error Correction With Neural Reinforcement Learning ”, Sakaguchi et al 2017
- “Noisy Networks for Exploration ”, Fortunato et al 2017
- “Gated-Attention Architectures for Task-Oriented Language Grounding ”, Chaplot et al 2017
- “The Persistence and Transience of Memory ”, Richards & Frankland 2017
- “Deep Reinforcement Learning from Human Preferences § Appendix A.2: Atari ”, Christiano et al 2017 (page 15 org openai)
- “Towards Synthesizing Complex Programs from Input-Output Examples ”, Chen et al 2017
- “IDK Cascades: Fast Deep Learning by Learning Not to Overthink ”, Wang et al 2017
- “Teaching Machines to Describe Images via Natural Language Feedback ”, Ling & Fidler 2017
- “Learning Time/Memory-Efficient Deep Architectures With Budgeted Super Networks ”, Veniat & Denoyer 2017
- “Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models ”, Guimaraes et al 2017
- “Ask the Right Questions: Active Question Reformulation With Reinforcement Learning ”, Buck et al 2017
- “A Deep Reinforced Model for Abstractive Summarization ”, Paulus et al 2017
- “Inferring and Executing Programs for Visual Reasoning ”, Johnson et al 2017
- “Time-Contrastive Networks: Self-Supervised Learning from Video ”, Sermanet et al 2017
- “RAM: Dynamic Computational Time for Visual Attention ”, Li et al 2017
- “Born to Learn: the Inspiration, Progress, and Future of Evolved Plastic Artificial Neural Networks (EPANNs) ”, Soltoggio et al 2017
- “Learning Cooperative Visual Dialog Agents With Deep Reinforcement Learning ”, Das et al 2017
- “Improving Neural Machine Translation With Conditional Sequence Generative Adversarial Nets ”, Yang et al 2017
- “End-To-End Optimization of Goal-Driven and Visually Grounded Dialogue Systems ”, Strub et al 2017
- “Neural Episodic Control ”, Pritzel et al 2017
- “CoDeepNEAT: Evolving Deep Neural Networks ”, Miikkulainen et al 2017
- “Tuning Recurrent Neural Networks With Reinforcement Learning ”, Jaques et al 2017
- “PathNet: Evolution Channels Gradient Descent in Super Neural Networks ”, Fernando et al 2017
- “Deep Reinforcement Learning: A Brief Survey ”, Arulkumaran et al 2017
- “Your TL;DR by an AI: A Deep Reinforced Model for Abstractive Summarization ”, Paulus 2017
- “Loss Is Its Own Reward: Self-Supervision for Reinforcement Learning ”, Shelhamer et al 2016
- “DeepMind Lab ”, Beattie et al 2016
- “Self-Critical Sequence Training for Image Captioning ”, Rennie et al 2016
- “Neural Combinatorial Optimization With Reinforcement Learning ”, Bello et al 2016
- “Reinforcement Learning With Unsupervised Auxiliary Tasks ”, Jaderberg et al 2016
- “A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models ”, Finn et al 2016
- “Hybrid Computing Using a Neural Network With Dynamic External Memory ”, Graves et al 2016
- “Connecting Generative Adversarial Networks and Actor-Critic Methods ”, Pfau & Vinyals 2016
- “Deep Reinforcement Learning for Mention-Ranking Coreference Models ”, Clark & Manning 2016
- “Deep Neural Networks for YouTube Recommendations ”, Covington et al 2016
- “The Malmo Platform for Artificial Intelligence Experimentation ”, Johnson et al 2016
- “Progressive Neural Networks ”, Rusu et al 2016
- “Learning to Optimize ”, Li & Malik 2016
- “Deep Reinforcement Learning for Dialogue Generation ”, Li et al 2016
- “ViZDoom: A Doom-Based AI Research Platform for Visual Reinforcement Learning ”, Kempka et al 2016
- “Learning from the Memory of Atari 2600 ”, Sygnowski & Michalewski 2016
- “Improving Information Extraction by Acquiring External Evidence With Reinforcement Learning ”, Narasimhan et al 2016
- “Asynchronous Methods for Deep Reinforcement Learning ”, Mnih et al 2016
- “Dueling Network Architectures for Deep Reinforcement Learning ”, Wang et al 2015
- “Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning ”, Parisotto et al 2015
- “Prioritized Experience Replay ”, Schaul et al 2015
- “Deep Reinforcement Learning With Double Q-Learning ”, Hasselt et al 2015
- “Gorila: Massively Parallel Methods for Deep Reinforcement Learning ”, Nair et al 2015
- “Reinforcement Learning Neural Turing Machines—Revised ”, Zaremba & Sutskever 2015
- “An Invitation to Imitation ”, Bagnell 2015
- “TRPO: Trust Region Policy Optimization ”, Schulman et al 2015
- “DRAW: A Recurrent Neural Network For Image Generation ”, Gregor et al 2015
- “Random Feedback Weights Support Learning in Deep Neural Networks ”, Lillicrap et al 2014
- “Learning to Execute ”, Zaremba & Sutskever 2014
- “Does Temporal Discounting Explain Unhealthy Behavior? A Systematic Review and Reinforcement Learning Perspective ”, Story et al 2014
- “Playing Atari With Deep Reinforcement Learning ”, Mnih et al 2013
- “The Arcade Learning Environment: An Evaluation Platform for General Agents ”, Bellemare et al 2012
- “Artist Agent: A Reinforcement Learning Approach to Automatic Stroke Generation in Oriental Ink Painting ”, Xie et al 2012
- “Off-Policy Actor-Critic ”, Degris et al 2012
- “Neural Mechanisms of Speed-Accuracy Tradeoff ”, Heitz & Schall 2012
- “Optimal Direct Policy Search ”, Glasmachers & Schmidhuber 2011
- “DAgger: A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning ”, Ross et al 2010
- “Compositional Pattern Producing Networks: A Novel Abstraction of Development ”, Stanley 2007
- “Midbrain Dopamine Neurons Encode a Quantitative Reward Prediction Error Signal ”, Bayer & Glimcher 2005
- “It Takes Two Neurons To Ride a Bicycle ”, Cook 2004
- “Evolution Strategies: A Comprehensive Introduction ”, Beyer & Schwefel 2002
- “Recent Developments in the Evolution of Morphologies and Controllers for Physically Simulated Creatures § A Re-Implementation of Sims’ Work Using the MathEngine Physics Engine ”, Taylor & Massey 2001 (page 6)
- “Learning to Drive a Bicycle Using Reinforcement Learning and Shaping ”, Randløv & Alstrøm 1998
- “6.6 Actor-Critic Methods ”, Sutton & Barto 1998
- “Descriptor Predictive Control: Tracking Controllers for a Riderless Bicycle ”, Wissel et al 1996
- “Control for an Autonomous Bicycle ”, Getz & Marsden 1995
- “On Learning How to Learn Learning Strategies: Technical Report FKI-198-94 (Revised) ”, Schmidhuber 1995
- “Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning ”, Williams 1992
- Proceedings of the First International Conference on Genetic Algorithms and Their Applications, Grefenstette 1985
- “Temporal Credit Assignment In Reinforcement Learning ”, Sutton 1984
- “Experiments on the Mechanization of Game-Learning Part II. Rule-Based Learning and the Human Window [BOXES] ”, Michie 1982
- “Why the Law of Effect Will Not Go Away ”, Dennett 1974
- “Experiments on the Mechanization of Game-Learning Part I. Characterization of the Model and Its Parameters [MENACE] ”, Michie 1963
- “A Matchbox Game-Learning Machine ”, Gardner 1962
- “Some Studies in Machine Learning Using the Game of Checkers ”, Samuel 1959
- “John Schulman’s Homepage ”, Schulman 2025
- “LA Residents Complain about ‘Waze Craze’ ”
- “Sutton & Barto Book: Reinforcement Learning: An Introduction ”, Sutton & Barto 2025
- “Evolving Stable Strategies ”, Ha 2025
- “Finding Nash Equilibria through Simulation ”
- “Deep Reinforcement Learning without Experience Replay, Target Networks, or Batch Updates ”
- Trackmania I—The History of Machine Learning in Trackmania
- “The 37 Implementation Details of Proximal Policy Optimization ”
- “David Ha Homepage ”, Ha 2025
- “@jeremy-Berman/arc-Agi on Params ”
- “Mathematical Discoveries from Program Search With Large Language Models ”
- “Microsoft and Meta Join Google in Using AI to Help Run Their Data Centers ”
- “Hedonic Loops and Taming RL ”, Millidge 2025
- “Sony’s Racing Car AI Just Destroyed Its Human Competitors—By Being Nice (And Fast) ”
- “Target-Driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning [Video] ”
- “Measuring the Intrinsic Dimension of Objective Landscapes [Video] ”
- “Zyme—An Evolvable Language ”
- Wikipedia (3)
- Miscellaneous
- Bibliography
See Also
Gwern
“The Kelly Coin-Flipping Game: Exact Solutions ”, Gwern et al 2017
Links
“Interpreting Emergent Planning in Model-Free Reinforcement Learning ”, Bush et al 2025
Interpreting Emergent Planning in Model-Free Reinforcement Learning
“2024 Turing Award: Andrew Barto & Richard Sutton ”, ACM 2025
“Training Language Models for Social Deduction With Multi-Agent Reinforcement Learning ”, Sarkar et al 2025
Training Language Models for Social Deduction with Multi-Agent Reinforcement Learning
“Value-Based Deep RL Scales Predictably ”, Rybkin et al 2025
“MR.Q: Towards General-Purpose Model-Free Reinforcement Learning ”, Fujimoto et al 2025
MR.Q: Towards General-Purpose Model-Free Reinforcement Learning
“Amplifying Human Performance in Combinatorial Competitive Programming ”, Veličković et al 2024
Amplifying human performance in combinatorial competitive programming
“Deep Reinforcement Learning Without Experience Replay, Target Networks, or Batch Updates ”, Elsayed et al 2024
Deep Reinforcement Learning Without Experience Replay, Target Networks, or Batch Updates
“Centaur: a Foundation Model of Human Cognition ”, Binz et al 2024
“SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning ”, Lee et al 2024
SimBa: Simplicity Bias for Scaling Up Parameters in Deep Reinforcement Learning
“Training Language Models to Self-Correct via Reinforcement Learning ”, Kumar et al 2024
Training Language Models to Self-Correct via Reinforcement Learning
“Carpentopod: A Walking Table Project ”, Carpentier 2024
“Mind Wandering During Implicit Learning Is Associated With Increased Periodic EEG Activity And Improved Extraction Of Hidden Probabilistic Patterns ”, Simor et al 2024
“Alexa Is in Millions of Households—And Amazon Is Losing Billions ”, Mattioli 2024
Alexa Is in Millions of Households—and Amazon Is Losing Billions
“Bigger, Regularized, Optimistic: Scaling for Compute and Sample-Efficient Continuous Control ”, Nauman et al 2024
Bigger, Regularized, Optimistic: scaling for compute and sample-efficient continuous control
“Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo ”, Zhao et al 2024
Probabilistic Inference in Language Models via Twisted Sequential Monte Carlo
“Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data ”, Tajwar et al 2024
Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data
“Automatic Design of Stigmergy-Based Behaviors for Robot Swarms ”, Salman et al 2024
Automatic design of stigmergy-based behaviors for robot swarms
“CodeIt: Self-Improving Language Models With Prioritized Hindsight Replay ”, Butt et al 2024
CodeIt: Self-Improving Language Models with Prioritized Hindsight Replay
“ReST Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent ”, Aksitov et al 2023
ReST meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent
“Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning ”, Dutta et al 2023
Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning
“Let Models Speak Ciphers: Multiagent Debate through Embeddings ”, Pham et al 2023
Let Models Speak Ciphers: Multiagent Debate through Embeddings
“Predictive Auxiliary Objectives in Deep RL Mimic Learning in the Brain ”, Fang & Stachenfeld 2023
Predictive auxiliary objectives in deep RL mimic learning in the brain
“Small Batch Deep Reinforcement Learning ”, Obando-Ceron et al 2023
“Maximum Diffusion Reinforcement Learning ”, Berrueta et al 2023
“Subwords As Skills: Tokenization for Sparse-Reward Reinforcement Learning ”, Yunis et al 2023
Subwords as Skills: Tokenization for Sparse-Reward Reinforcement Learning
“Comparative Study of Model-Based and Model-Free Reinforcement Learning Control Performance in HVAC Systems ”, Gao & Wang 2023
“What Are Dreams For? Converging Lines of Research Suggest That We Might Be Misunderstanding Something We Do Every Night of Our Lives ”, Gefter 2023
“Learning to Model the World With Language ”, Lin et al 2023
“Low-Poly Image Generation Using Evolutionary Algorithms in Ruby ”
Low-Poly Image Generation using Evolutionary Algorithms in Ruby :
“Parallel Q-Learning (PQL): Scaling Off-Policy Reinforcement Learning under Massively Parallel Simulation ”, Li et al 2023
“Using Temperature to Analyze the Neural Basis of a Time-Based Decision ”, Monteiro et al 2023
Using temperature to analyze the neural basis of a time-based decision
“Minigrid & Miniworld: Modular & Customizable Reinforcement Learning Environments for Goal-Oriented Tasks ”, Chevalier-Boisvert et al 2023
“Twitching in Sensorimotor Development from Sleeping Rats to Robots ”, Blumberg et al 2023
Twitching in Sensorimotor Development from Sleeping Rats to Robots
“Universal Mechanical Polycomputation in Granular Matter ”, Parsa et al 2023
“Lucy-SKG: Learning to Play Rocket League Efficiently Using Deep Reinforcement Learning ”, Moschopoulos et al 2023
Lucy-SKG: Learning to Play Rocket League Efficiently Using Deep Reinforcement Learning
“Improving Language Models With Advantage-Based Offline Policy Gradients ”, Baheti et al 2023
Improving Language Models with Advantage-based Offline Policy Gradients
“Micromouse: The Fastest Maze-Solving Competition On Earth ”, Veritasium 2023
“Reinforcement Learning in Newcomb-Like Environments ”, Bell et al 2023
“WizardLM: Empowering Large Language Models to Follow Complex Instructions ”, Xu et al 2023
WizardLM: Empowering Large Language Models to Follow Complex Instructions
“Bridging Discrete and Backpropagation: Straight-Through and Beyond ”, Liu et al 2023
Bridging Discrete and Backpropagation: Straight-Through and Beyond
“Empirical Design in Reinforcement Learning ”, Patterson et al 2023
“A Circuit Mechanism Linking past and Future Learning through Shifts in Perception ”, Crossley et al 2023
A circuit mechanism linking past and future learning through shifts in perception
“Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier ”, D’Oro et al 2023
Sample-Efficient Reinforcement Learning by Breaking the Replay Ratio Barrier
“Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula ”, Bronstein et al 2022
Embedding Synthetic Off-Policy Experience for Autonomous Driving via Zero-Shot Curricula
“Melting Pot 2.0 ”, Agapiou et al 2022
“Token Turing Machines ”, Ryoo et al 2022
“Legged Locomotion in Challenging Terrains Using Egocentric Vision ”, Agarwal et al 2022
Legged Locomotion in Challenging Terrains using Egocentric Vision
“Over-Communicate No More: Situated RL Agents Learn Concise Communication Protocols ”, Kalinowska et al 2022
Over-communicate no more: Situated RL agents learn concise communication protocols
“E3B: Exploration via Elliptical Episodic Bonuses ”, Henaff et al 2022
“Hyperbolic Deep Reinforcement Learning ”, Cetin et al 2022
“Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization ”, Ramamurthy et al 2022
“Dynamic Prompt Learning via Policy Gradient for Semi-Structured Mathematical Reasoning ”, Lu et al 2022
Dynamic Prompt Learning via Policy Gradient for Semi-structured Mathematical Reasoning
“Simplifying Model-Based RL: Learning Representations, Latent-Space Models, and Policies With One Objective (ALM) ”, Ghugare et al 2022
“Human-Level Atari 200× Faster ”, Kapturowski et al 2022
“Nearest Neighbor Non-Autoregressive Text Generation ”, Niwa et al 2022
“A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning ”, Dann et al 2022
A Provably Efficient Model-Free Posterior Sampling Method for Episodic Reinforcement Learning
“Learning to Generalize With Object-Centric Agents in the Open World Survival Game Crafter ”, Stanić et al 2022
Learning to Generalize with Object-centric Agents in the Open World Survival Game Crafter
“Improved Policy Optimization for Online Imitation Learning ”, Lavington et al 2022
“Offline RL for Natural Language Generation With Implicit Language Q Learning ”, Snell et al 2022
Offline RL for Natural Language Generation with Implicit Language Q Learning
“Fine-Grained Image Captioning With CLIP Reward ”, Cho et al 2022
“Reward Bases: Instantaneous Reward Revaluation With Temporal Difference Learning ”, Millidge et al 2022
Reward Bases: Instantaneous reward revaluation with temporal difference learning
“Is Vanilla Policy Gradient Overlooked? Analyzing Deep Reinforcement Learning for Hanabi ”, Grooten et al 2022
Is Vanilla Policy Gradient Overlooked? Analyzing Deep Reinforcement Learning for Hanabi
“Quantifying and Alleviating Political Bias in Language Models ”, Liu et al 2022c
Quantifying and alleviating political bias in language models
“Machine Learning Helps Control Tokamak Plasmas ”, Georgescu 2022
“Retrieval-Augmented Reinforcement Learning ”, Goyal et al 2022
“Policy Learning and Evaluation With Randomized Quasi-Monte Carlo ”, Arnold et al 2022
Policy Learning and Evaluation with Randomized Quasi-Monte Carlo
“A Data-Driven Approach for Learning to Control Computers ”, Humphreys et al 2022
“Magnetic Control of Tokamak Plasmas through Deep Reinforcement Learning ”, Degrave et al 2022
Magnetic control of tokamak plasmas through deep reinforcement learning
“Why Should I Trust You, Bellman? The Bellman Error Is a Poor Replacement for Value Error ”, Fujimoto et al 2022
Why Should I Trust You, Bellman? The Bellman Error is a Poor Replacement for Value Error
“Learning Dynamics and Generalization in Deep Reinforcement Learning ”, Lyle et al 2022
Learning Dynamics and Generalization in Deep Reinforcement Learning
“Agile Locomotion via Model-Free Learning ”, Margolis 2022
“Amortized Noisy Channel Neural Machine Translation ”, Pang et al 2021
“Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs ”, Korkmaz 2021
Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs
“Residual Pathway Priors for Soft Equivariance Constraints ”, Finzi et al 2021
“Simple but Effective: CLIP Embeddings for Embodied AI ”, Khandelwal et al 2021
“Offline Reinforcement Learning With Implicit Q-Learning (IQL) ”, Kostrikov et al 2021
Offline Reinforcement Learning with Implicit Q-Learning (IQL)
“Recurrent Model-Free RL Is a Strong Baseline for Many POMDPs ”, Ni et al 2021
Recurrent Model-Free RL is a Strong Baseline for Many POMDPs
“DroQ: Dropout Q-Functions for Doubly Efficient Reinforcement Learning ”, Hiraoka et al 2021
DroQ: Dropout Q-Functions for Doubly Efficient Reinforcement Learning
“Batch Size-Invariance for Policy Optimization ”, Hilton et al 2021
“MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research ”, Samvelyan et al 2021
MiniHack the Planet: A Sandbox for Open-Ended Reinforcement Learning Research
“Bootstrapped Meta-Learning ”, Flennerhag et al 2021
“Megaverse: Simulating Embodied Agents at One Million Experiences per Second ”, Petrenko et al 2021
Megaverse: Simulating Embodied Agents at One Million Experiences per Second
“PES: Unbiased Gradient Estimation in Unrolled Computation Graphs With Persistent Evolution Strategies ”, Vicol et al 2021
“Multi-Task Curriculum Learning in a Complex, Visual, Hard-Exploration Domain: Minecraft ”, Kanitscheider et al 2021
Multi-task curriculum learning in a complex, visual, hard-exploration domain: Minecraft
“On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning ”, Vischer et al 2021
On Lottery Tickets and Minimal Task Representations in Deep Reinforcement Learning
“Constructions in Combinatorics via Neural Networks ”, Wagner 2021
“Muesli: Combining Improvements in Policy Optimization ”, Hessel et al 2021
“Podracer Architectures for Scalable Reinforcement Learning ”, Hessel et al 2021
“Counter-Strike Deathmatch With Large-Scale Behavioral Cloning ”, Pearce & Zhu 2021
Counter-Strike Deathmatch with Large-Scale Behavioral Cloning
“ALD: Efficient Transformers in Reinforcement Learning Using Actor-Learner Distillation ”, Parisotto & Salakhutdinov 2021
ALD: Efficient Transformers in Reinforcement Learning using Actor-Learner Distillation
“Replay in Deep Learning: Current Approaches and Missing Biological Elements ”, Hayes et al 2021
Replay in Deep Learning: Current Approaches and Missing Biological Elements
“Large Batch Simulation for Deep Reinforcement Learning ”, Shacklett et al 2021
“The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games ”, Yu et al 2021
The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games
“Reinforcement Learning for Datacenter Congestion Control ”, Tessler et al 2021
“Training Larger Networks for Deep Reinforcement Learning ”, Ota et al 2021
“How RL Agents Behave When Their Actions Are Modified ”, Langlois & Everitt 2021
“A✱ Search Without Expansions: Learning Heuristic Functions With Deep Q-Networks ”, Agostinelli et al 2021
A✱ Search Without Expansions: Learning Heuristic Functions with Deep Q-Networks
“Randomized Ensembled Double Q-Learning (REDQ): Learning Fast Without a Model ”, Chen et al 2021
Randomized Ensembled Double Q-Learning (REDQ): Learning Fast Without a Model
“MLGO: a Machine Learning Guided Compiler Optimizations Framework ”, Trofin et al 2021
MLGO: a Machine Learning Guided Compiler Optimizations Framework
“Evolving Reinforcement Learning Algorithms ”, Co-Reyes et al 2021
“Using Deep Reinforcement Learning to Reveal How the Brain Encodes Abstract State-Space Representations in High-Dimensional Environments ”, Cross 2020
“Autonomous Navigation of Stratospheric Balloons Using Reinforcement Learning ”, Bellemare et al 2020
Autonomous navigation of stratospheric balloons using reinforcement learning
“A Unified Framework for Dopamine Signals across Timescales ”, Kim et al 2020
“Offline Learning from Demonstrations and Unlabeled Experience ”, Zolna et al 2020
Offline Learning from Demonstrations and Unlabeled Experience
“Adversarial Vulnerabilities of Human Decision-Making ”, Dezfouli et al 2020
“D2RL: Deep Dense Architectures in Reinforcement Learning ”, Sinha et al 2020
“Human-Centric Dialog Training via Offline Reinforcement Learning ”, Jaques et al 2020
Human-centric Dialog Training via Offline Reinforcement Learning
“Emergent Social Learning via Multi-Agent Reinforcement Learning ”, Ndousse et al 2020
Emergent Social Learning via Multi-agent Reinforcement Learning
“Super-Human Performance in Gran Turismo Sport Using Deep Reinforcement Learning ”, Fuchs et al 2020
Super-Human Performance in Gran Turismo Sport Using Deep Reinforcement Learning
“SPR: Data-Efficient Reinforcement Learning With Self-Predictive Representations ”, Schwarzer et al 2020
SPR: Data-Efficient Reinforcement Learning with Self-Predictive Representations
“Learning Breakout From RAM—Part 2 ”, philoxenic 2020
“Learning Breakout From RAM—Part 1 ”, philoxenic 2020
“Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks ”, Papoudakis et al 2020
Benchmarking Multi-Agent Deep Reinforcement Learning Algorithms in Cooperative Tasks
“Improving GAN Training With Probability Ratio Clipping and Sample Reweighting ”, Wu et al 2020
Improving GAN Training with Probability Ratio Clipping and Sample Reweighting
“Conservative Q-Learning for Offline Reinforcement Learning ”, Kumar et al 2020
“Controlling Overestimation Bias With Truncated Mixture of Continuous Distributional Quantile Critics (TQC) ”, Kuznetsov et al 2020
“Evaluating the Rainbow DQN Agent in Hanabi With Unseen Partners ”, Canaan et al 2020
Evaluating the Rainbow DQN Agent in Hanabi with Unseen Partners
“Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels ”, Kostrikov et al 2020
Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels
“Chip Placement With Deep Reinforcement Learning ”, Mirhoseini et al 2020
“CURL: Contrastive Unsupervised Representations for Reinforcement Learning ”, Srinivas et al 2020
CURL: Contrastive Unsupervised Representations for Reinforcement Learning
“Evolving Normalization-Activation Layers ”, Liu et al 2020
“Benchmarking End-To-End Behavioral Cloning on Video Games ”, Kanervisto et al 2020
“Agent57: Outperforming the Atari Human Benchmark ”, Badia et al 2020
“Deep Neuroethology of a Virtual Rodent ”, Merel et al 2020
“Q✱ Approximation Schemes for Batch Reinforcement Learning: A Theoretical Comparison ”, Xie & Jiang 2020
Q✱ Approximation Schemes for Batch Reinforcement Learning: A Theoretical Comparison
“Can Increasing Input Dimensionality Improve Deep Reinforcement Learning? ”, Ota et al 2020
Can Increasing Input Dimensionality Improve Deep Reinforcement Learning?
“Causal Evidence Supporting the Proposal That Dopamine Transients Function As Temporal Difference Prediction Errors ”, Maes et al 2020
“A Distributional Code for Value in Dopamine-Based Reinforcement Learning ”, Dabney et al 2020
A distributional code for value in dopamine-based reinforcement learning :
View PDF (19MB):
“Combining Q-Learning and Search With Amortized Value Estimates ”, Hamrick et al 2019
Combining Q-Learning and Search with Amortized Value Estimates
“SEED RL: Scalable and Efficient Deep-RL With Accelerated Central Inference ”, Espeholt et al 2019
SEED RL: Scalable and Efficient Deep-RL with Accelerated Central Inference
“Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning? ”, Du et al 2019
Is a Good Representation Sufficient for Sample Efficient Reinforcement Learning?
“QUARL: Quantized Reinforcement Learning (ActorQ) ”, Lam et al 2019
“Deep Learning Enables Rapid Identification of Potent DDR1 Kinase Inhibitors ”, Zhavoronkov et al 2019
Deep learning enables rapid identification of potent DDR1 kinase inhibitors :
“Exponential Slowdown for Larger Populations: The (μ+1)-EA on Monotone Functions ”, Lengler & Zou 2019
Exponential slowdown for larger populations: The (μ+1)-EA on monotone functions
“Is Deep Reinforcement Learning Really Superhuman on Atari? Leveling the Playing Field ”, Toromanoff et al 2019
Is Deep Reinforcement Learning Really Superhuman on Atari? Leveling the playing field
“A View on Deep Reinforcement Learning in System Optimization ”, Haj-Ali et al 2019
A View on Deep Reinforcement Learning in System Optimization
“Playing the Lottery With Rewards and Multiple Languages: Lottery Tickets in RL and NLP ”, Yu et al 2019
Playing the lottery with rewards and multiple languages: lottery tickets in RL and NLP
“A General Dichotomy of Evolutionary Algorithms on Monotone Functions ”, Lengler 2019
A General Dichotomy of Evolutionary Algorithms on Monotone Functions
“A Recipe for Training Neural Networks ”, Karpathy 2019
“Universal Quantum Control through Deep Reinforcement Learning ”, Niu et al 2019
Universal quantum control through deep reinforcement learning
“Reinforcement Learning for Recommender Systems: A Case Study on Youtube ”, Chen 2019
Reinforcement Learning for Recommender Systems: A Case Study on Youtube
“Benchmarking Classic and Learned Navigation in Complex 3D Environments ”, Mishkin et al 2019
Benchmarking Classic and Learned Navigation in Complex 3D Environments
“AutoPhase: Compiler Phase-Ordering for High Level Synthesis With Deep Reinforcement Learning ”, Haj-Ali et al 2019
AutoPhase: Compiler Phase-Ordering for High Level Synthesis with Deep Reinforcement Learning
“DRC: An Investigation of Model-Free Planning ”, Guez et al 2019
“Anxiety, Depression, and Decision Making: A Computational Perspective ”, Bishop & Gagne 2019
Anxiety, Depression, and Decision Making: A Computational Perspective
“Reinforcement Learning in Artificial and Biological Systems ”, Neftci & Averbeck 2019
Reinforcement learning in artificial and biological systems :
“Designing Neural Networks through Neuroevolution ”, Stanley et al 2019
“The Credit Assignment Problem ”, Demski 2019
“IRLAS: Inverse Reinforcement Learning for Architecture Search ”, Guo et al 2018
IRLAS: Inverse Reinforcement Learning for Architecture Search
“Quantifying Generalization in Reinforcement Learning ”, Cobbe et al 2018
“Top-K Off-Policy Correction for a REINFORCE Recommender System ”, Chen et al 2018
Top-K Off-Policy Correction for a REINFORCE Recommender System
“Relative Entropy Regularized Policy Iteration ”, Abdolmaleki et al 2018
“ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware ”, Cai et al 2018
ProxylessNAS: Direct Neural Architecture Search on Target Task and Hardware
“Neural Probabilistic Motor Primitives for Humanoid Control ”, Merel et al 2018
“InstaNAS: Instance-Aware Neural Architecture Search ”, Cheng et al 2018
“A Closer Look at Deep Policy Gradients ”, Ilyas et al 2018
“One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets With RL ”, Paine et al 2018
One-Shot High-Fidelity Imitation: Training Large-Scale Deep Nets with RL
“Reinforcement Learning for Improving Agent Design ”, Ha 2018
“Reinforcement Learning for Improving Agent Design [Homepage] ”, Ha 2018
Reinforcement Learning for Improving Agent Design [homepage] :
“Variational Discriminator Bottleneck: Improving Imitation Learning, Inverse RL, and GANs by Constraining Information Flow ”, Peng et al 2018
“Learning to Perform Local Rewriting for Combinatorial Optimization ”, Chen & Tian 2018
Learning to Perform Local Rewriting for Combinatorial Optimization
“R2D2: Recurrent Experience Replay in Distributed Reinforcement Learning ”, Kapturowski et al 2018
R2D2: Recurrent Experience Replay in Distributed Reinforcement Learning
“Benchmarking Reinforcement Learning Algorithms on Real-World Robots ”, Mahmood et al 2018
Benchmarking Reinforcement Learning Algorithms on Real-World Robots
“Deterministic Implementations for Reproducibility in Deep Reinforcement Learning ”, Nagarajan et al 2018
Deterministic Implementations for Reproducibility in Deep Reinforcement Learning
“Multi-Task Deep Reinforcement Learning With PopArt ”, Hessel et al 2018
“Accelerated Reinforcement Learning for Sentence Generation by Vocabulary Prediction ”, Hashimoto & Tsuruoka 2018
Accelerated Reinforcement Learning for Sentence Generation by Vocabulary Prediction
“Searching Toward Pareto-Optimal Device-Aware Neural Architectures ”, Cheng et al 2018
Searching Toward Pareto-Optimal Device-Aware Neural Architectures
“A Study of Reinforcement Learning for Neural Machine Translation ”, Wu et al 2018
A Study of Reinforcement Learning for Neural Machine Translation
“Improving Abstraction in Text Summarization ”, Kryściński et al 2018
“Learning to Optimize Join Queries With Deep Reinforcement Learning ”, Krishnan et al 2018
Learning to Optimize Join Queries With Deep Reinforcement Learning
“InfoNCE: Representation Learning With Contrastive Predictive Coding (CPC) ”, Oord et al 2018
InfoNCE: Representation Learning with Contrastive Predictive Coding (CPC)
“Is Q-Learning Provably Efficient? ”, Jin et al 2018
“Maximum a Posteriori Policy Optimization ”, Abdolmaleki et al 2018
“The Unusual Effectiveness of Averaging in GAN Training ”, Yazıcı et al 2018
“Resource-Efficient Neural Architect ”, Zhou et al 2018
“DVRL: Deep Variational Reinforcement Learning for POMDPs ”, Igl et al 2018
“Playing Atari With Six Neurons ”, Cuccu et al 2018
“Measuring the Intrinsic Dimension of Objective Landscapes ”, Li et al 2018
“DP4G: Distributed Distributional Deterministic Policy Gradients ”, Barth-Maron et al 2018
DP4G: Distributed Distributional Deterministic Policy Gradients
“Optimizing Query Evaluations Using Reinforcement Learning for Web Search ”, Rosset et al 2018
Optimizing Query Evaluations using Reinforcement Learning for Web Search
“Simple Random Search Provides a Competitive Approach to Reinforcement Learning ”, Mania et al 2018
Simple random search provides a competitive approach to reinforcement learning
“Delayed Impact of Fair Machine Learning ”, Liu et al 2018
“Accelerated Methods for Deep Reinforcement Learning ”, Stooke & Abbeel 2018
“Learning Memory Access Patterns ”, Hashemi et al 2018
“Investigating Human Priors for Playing Video Game ”, Dubey et al 2018
“ME-TRPO: Model-Ensemble Trust-Region Policy Optimization ”, Kurutach et al 2018
“TD3: Addressing Function Approximation Error in Actor-Critic Methods ”, Fujimoto et al 2018
TD3: Addressing Function Approximation Error in Actor-Critic Methods
“Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration ”, Liu et al 2018
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration
“Unicorn: Continual Learning With a Universal, Off-Policy Agent ”, Mankowitz et al 2018
Unicorn: Continual Learning with a Universal, Off-policy Agent
“ENAS: Efficient Neural Architecture Search via Parameter Sharing ”, Pham et al 2018
ENAS: Efficient Neural Architecture Search via Parameter Sharing
“Regularized Evolution for Image Classifier Architecture Search ”, Real et al 2018
Regularized Evolution for Image Classifier Architecture Search
“IMPALA: Scalable Distributed Deep-RL With Importance Weighted Actor-Learner Architectures ”, Espeholt et al 2018
IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures
“Interactive Grounded Language Acquisition and Generalization in a 2D World ”, Yu et al 2018
Interactive Grounded Language Acquisition and Generalization in a 2D World
“Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning With a Stochastic Actor ”, Haarnoja et al 2018
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
“Chapter 5: Monte Carlo Methods ”, Sutton & Barto 2018 (page 133)
“Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning ”, Such et al 2017
“The Case for Learned Index Structures ”, Kraska et al 2017
“AI Safety Gridworlds ”, Leike et al 2017
“Classification With Costly Features Using Deep Reinforcement Learning ”, Janisch et al 2017
Classification with Costly Features using Deep Reinforcement Learning
“Reinforcement Learning of Speech Recognition System Based on Policy Gradient and Hypothesis Selection ”, Kato & Shinozaki 2017
“Towards the Use of Deep Reinforcement Learning With Global Policy For Query-Based Extractive Summarization ”, Molla 2017
“Swish: Searching for Activation Functions ”, Ramachandran et al 2017
“Gradient-Free Policy Architecture Search and Adaptation ”, Ebrahimi et al 2017
“Rainbow: Combining Improvements in Deep Reinforcement Learning ”, Hessel et al 2017
Rainbow: Combining Improvements in Deep Reinforcement Learning
“OptionGAN: Learning Joint Reward-Policy Options Using Generative Adversarial Inverse Reinforcement Learning ”, Henderson et al 2017
“Deep Reinforcement Learning That Matters ”, Henderson et al 2017
“Revisiting the Arcade Learning Environment: Evaluation Protocols and Open Problems for General Agents ”, Machado et al 2017
“Seq2SQL: Generating Structured Queries from Natural Language Using Reinforcement Learning ”, Zhong et al 2017
Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning
“The Successor Representation in Human Reinforcement Learning ”, Momennejad et al 2017
The successor representation in human reinforcement learning
“Practical Block-Wise Neural Network Architecture Generation ”, Zhong et al 2017
“Learning Policies for Adaptive Tracking With Deep Feature Cascades ”, Huang et al 2017
Learning Policies for Adaptive Tracking with Deep Feature Cascades
“Reinforced Video Captioning With Entailment Rewards ”, Pasunuru & Bansal 2017
“A Distributional Perspective on Reinforcement Learning ”, Bellemare et al 2017
“Tracking As Online Decision-Making: Learning a Policy from Streaming Videos With Reinforcement Learning ”, III & Ramanan 2017
“Trial without Error: Towards Safe Reinforcement Learning via Human Intervention ”, Saunders et al 2017
Trial without Error: Towards Safe Reinforcement Learning via Human Intervention
“Efficient Architecture Search by Network Transformation ”, Cai et al 2017
“Grammatical Error Correction With Neural Reinforcement Learning ”, Sakaguchi et al 2017
Grammatical Error Correction with Neural Reinforcement Learning
“Noisy Networks for Exploration ”, Fortunato et al 2017
“Gated-Attention Architectures for Task-Oriented Language Grounding ”, Chaplot et al 2017
Gated-Attention Architectures for Task-Oriented Language Grounding
“The Persistence and Transience of Memory ”, Richards & Frankland 2017
“Deep Reinforcement Learning from Human Preferences § Appendix A.2: Atari ”, Christiano et al 2017 (page 15 org openai)
Deep reinforcement learning from human preferences § Appendix A.2: Atari
“Towards Synthesizing Complex Programs from Input-Output Examples ”, Chen et al 2017
Towards Synthesizing Complex Programs from Input-Output Examples
“IDK Cascades: Fast Deep Learning by Learning Not to Overthink ”, Wang et al 2017
IDK Cascades: Fast Deep Learning by Learning not to Overthink
“Teaching Machines to Describe Images via Natural Language Feedback ”, Ling & Fidler 2017
Teaching Machines to Describe Images via Natural Language Feedback
“Learning Time/Memory-Efficient Deep Architectures With Budgeted Super Networks ”, Veniat & Denoyer 2017
Learning Time/Memory-Efficient Deep Architectures with Budgeted Super Networks
“Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models ”, Guimaraes et al 2017
Objective-Reinforced Generative Adversarial Networks (ORGAN) for Sequence Generation Models
“Ask the Right Questions: Active Question Reformulation With Reinforcement Learning ”, Buck et al 2017
Ask the Right Questions: Active Question Reformulation with Reinforcement Learning
“A Deep Reinforced Model for Abstractive Summarization ”, Paulus et al 2017
“Inferring and Executing Programs for Visual Reasoning ”, Johnson et al 2017
“Time-Contrastive Networks: Self-Supervised Learning from Video ”, Sermanet et al 2017
Time-Contrastive Networks: Self-Supervised Learning from Video
“RAM: Dynamic Computational Time for Visual Attention ”, Li et al 2017
“Born to Learn: the Inspiration, Progress, and Future of Evolved Plastic Artificial Neural Networks (EPANNs) ”, Soltoggio et al 2017
“Learning Cooperative Visual Dialog Agents With Deep Reinforcement Learning ”, Das et al 2017
Learning Cooperative Visual Dialog Agents with Deep Reinforcement Learning
“Improving Neural Machine Translation With Conditional Sequence Generative Adversarial Nets ”, Yang et al 2017
Improving Neural Machine Translation with Conditional Sequence Generative Adversarial Nets
“End-To-End Optimization of Goal-Driven and Visually Grounded Dialogue Systems ”, Strub et al 2017
End-to-end optimization of goal-driven and visually grounded dialogue systems
“Neural Episodic Control ”, Pritzel et al 2017
“CoDeepNEAT: Evolving Deep Neural Networks ”, Miikkulainen et al 2017
“Tuning Recurrent Neural Networks With Reinforcement Learning ”, Jaques et al 2017
Tuning Recurrent Neural Networks with Reinforcement Learning
“PathNet: Evolution Channels Gradient Descent in Super Neural Networks ”, Fernando et al 2017
PathNet: Evolution Channels Gradient Descent in Super Neural Networks
“Deep Reinforcement Learning: A Brief Survey ”, Arulkumaran et al 2017
“Your TL;DR by an AI: A Deep Reinforced Model for Abstractive Summarization ”, Paulus 2017
Your TL;DR by an AI: A Deep Reinforced Model for Abstractive Summarization
“Loss Is Its Own Reward: Self-Supervision for Reinforcement Learning ”, Shelhamer et al 2016
Loss is its own Reward: Self-Supervision for Reinforcement Learning
“DeepMind Lab ”, Beattie et al 2016
“Self-Critical Sequence Training for Image Captioning ”, Rennie et al 2016
“Neural Combinatorial Optimization With Reinforcement Learning ”, Bello et al 2016
Neural Combinatorial Optimization with Reinforcement Learning
“Reinforcement Learning With Unsupervised Auxiliary Tasks ”, Jaderberg et al 2016
“A Connection between Generative Adversarial Networks, Inverse Reinforcement Learning, and Energy-Based Models ”, Finn et al 2016
“Hybrid Computing Using a Neural Network With Dynamic External Memory ”, Graves et al 2016
Hybrid computing using a neural network with dynamic external memory
“Connecting Generative Adversarial Networks and Actor-Critic Methods ”, Pfau & Vinyals 2016
Connecting Generative Adversarial Networks and Actor-Critic Methods
“Deep Reinforcement Learning for Mention-Ranking Coreference Models ”, Clark & Manning 2016
Deep Reinforcement Learning for Mention-Ranking Coreference Models
“Deep Neural Networks for YouTube Recommendations ”, Covington et al 2016
“The Malmo Platform for Artificial Intelligence Experimentation ”, Johnson et al 2016
The Malmo Platform for Artificial Intelligence Experimentation
“Progressive Neural Networks ”, Rusu et al 2016
“Learning to Optimize ”, Li & Malik 2016
“Deep Reinforcement Learning for Dialogue Generation ”, Li et al 2016
“ViZDoom: A Doom-Based AI Research Platform for Visual Reinforcement Learning ”, Kempka et al 2016
ViZDoom: A Doom-based AI Research Platform for Visual Reinforcement Learning
“Learning from the Memory of Atari 2600 ”, Sygnowski & Michalewski 2016
“Improving Information Extraction by Acquiring External Evidence With Reinforcement Learning ”, Narasimhan et al 2016
Improving Information Extraction by Acquiring External Evidence with Reinforcement Learning
“Asynchronous Methods for Deep Reinforcement Learning ”, Mnih et al 2016
“Dueling Network Architectures for Deep Reinforcement Learning ”, Wang et al 2015
Dueling Network Architectures for Deep Reinforcement Learning
“Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning ”, Parisotto et al 2015
Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning
“Prioritized Experience Replay ”, Schaul et al 2015
“Deep Reinforcement Learning With Double Q-Learning ”, Hasselt et al 2015
“Gorila: Massively Parallel Methods for Deep Reinforcement Learning ”, Nair et al 2015
Gorila: Massively Parallel Methods for Deep Reinforcement Learning
“Reinforcement Learning Neural Turing Machines—Revised ”, Zaremba & Sutskever 2015
“An Invitation to Imitation ”, Bagnell 2015
“TRPO: Trust Region Policy Optimization ”, Schulman et al 2015
“DRAW: A Recurrent Neural Network For Image Generation ”, Gregor et al 2015
“Random Feedback Weights Support Learning in Deep Neural Networks ”, Lillicrap et al 2014
Random feedback weights support learning in deep neural networks
“Learning to Execute ”, Zaremba & Sutskever 2014
“Does Temporal Discounting Explain Unhealthy Behavior? A Systematic Review and Reinforcement Learning Perspective ”, Story et al 2014
“Playing Atari With Deep Reinforcement Learning ”, Mnih et al 2013
“The Arcade Learning Environment: An Evaluation Platform for General Agents ”, Bellemare et al 2012
The Arcade Learning Environment: An Evaluation Platform for General Agents
“Artist Agent: A Reinforcement Learning Approach to Automatic Stroke Generation in Oriental Ink Painting ”, Xie et al 2012
“Off-Policy Actor-Critic ”, Degris et al 2012
“Neural Mechanisms of Speed-Accuracy Tradeoff ”, Heitz & Schall 2012
“Optimal Direct Policy Search ”, Glasmachers & Schmidhuber 2011
“DAgger: A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning ”, Ross et al 2010
DAgger: A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
“Compositional Pattern Producing Networks: A Novel Abstraction of Development ”, Stanley 2007
Compositional pattern producing networks: A novel abstraction of development
“Midbrain Dopamine Neurons Encode a Quantitative Reward Prediction Error Signal ”, Bayer & Glimcher 2005
Midbrain dopamine neurons encode a quantitative reward prediction error signal
“It Takes Two Neurons To Ride a Bicycle ”, Cook 2004
“Evolution Strategies: A Comprehensive Introduction ”, Beyer & Schwefel 2002
“Recent Developments in the Evolution of Morphologies and Controllers for Physically Simulated Creatures § A Re-Implementation of Sims’ Work Using the MathEngine Physics Engine ”, Taylor & Massey 2001 (page 6)
“Learning to Drive a Bicycle Using Reinforcement Learning and Shaping ”, Randløv & Alstrøm 1998
Learning to Drive a Bicycle Using Reinforcement Learning and Shaping
“6.6 Actor-Critic Methods ”, Sutton & Barto 1998
“Descriptor Predictive Control: Tracking Controllers for a Riderless Bicycle ”, Wissel et al 1996
Descriptor predictive control: Tracking controllers for a riderless bicycle
“Control for an Autonomous Bicycle ”, Getz & Marsden 1995
“On Learning How to Learn Learning Strategies: Technical Report FKI-198-94 (Revised) ”, Schmidhuber 1995
On Learning How to Learn Learning Strategies: Technical Report FKI-198-94 (revised)
“Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning ”, Williams 1992
Simple statistical gradient-following algorithms for connectionist reinforcement learning
Proceedings of the First International Conference on Genetic Algorithms and Their Applications, Grefenstette 1985
Proceedings of the First International Conference on Genetic Algorithms and Their Applications :
“Temporal Credit Assignment In Reinforcement Learning ”, Sutton 1984
“Experiments on the Mechanization of Game-Learning Part II. Rule-Based Learning and the Human Window [BOXES] ”, Michie 1982
“Why the Law of Effect Will Not Go Away ”, Dennett 1974
“Experiments on the Mechanization of Game-Learning Part I. Characterization of the Model and Its Parameters [MENACE] ”, Michie 1963
“A Matchbox Game-Learning Machine ”, Gardner 1962
“Some Studies in Machine Learning Using the Game of Checkers ”, Samuel 1959
“John Schulman’s Homepage ”, Schulman 2025
“LA Residents Complain about ‘Waze Craze’ ”
“Sutton & Barto Book: Reinforcement Learning: An Introduction ”, Sutton & Barto 2025
Sutton & Barto Book: Reinforcement Learning: An Introduction
“Evolving Stable Strategies ”, Ha 2025
View External Link:
https://blog.otoro.net/2017/11/12/evolving-stable-strategies/
“Finding Nash Equilibria through Simulation ”
“Deep Reinforcement Learning without Experience Replay, Target Networks, or Batch Updates ”
Deep reinforcement learning without experience replay, target networks, or batch updates :
View HTML (49MB):
/doc/www/github.com/3156f32ffd8a984d68ba28cd47bf6aa10895e664.html
Trackmania I—The History of Machine Learning in Trackmania
Trackmania I—The History of Machine Learning in Trackmania :
“The 37 Implementation Details of Proximal Policy Optimization ”
The 37 Implementation Details of Proximal Policy Optimization :
View External Link:
https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
“David Ha Homepage ”, Ha 2025
“@jeremy-Berman/arc-Agi on Params ”
“Mathematical Discoveries from Program Search With Large Language Models ”
Mathematical discoveries from program search with large language models
“Microsoft and Meta Join Google in Using AI to Help Run Their Data Centers ”
Microsoft and Meta join Google in using AI to help run their data centers :
“Hedonic Loops and Taming RL ”, Millidge 2025
“Sony’s Racing Car AI Just Destroyed Its Human Competitors—By Being Nice (And Fast) ”
Sony’s racing car AI just destroyed its human competitors—by being nice (and fast) :
“Target-Driven Visual Navigation in Indoor Scenes Using Deep Reinforcement Learning [Video] ”
Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning [video]
“Measuring the Intrinsic Dimension of Objective Landscapes [Video] ”
Measuring the Intrinsic Dimension of Objective Landscapes [video] :
“Zyme—An Evolvable Language ”
Wikipedia (3)
Miscellaneous
/doc/reinforcement-learning/model-free/2021-hessel-figure4-anakinsebulbatpupodperformance.jpg:/doc/reinforcement-learning/armstrong-controlproblem/index.htmlhttp://vision.psych.umn.edu/groups/schraterlab/dearden98bayesian.pdfhttps://github.com/curiousjp/toy_sd_genetics?tab=readme-ov-file#toy_sd_geneticshttps://github.com/deepmind/acme/tree/master/acme/agents/tf/dmpohttps://www.lesswrong.com/posts/S54HKhxQyttNLATKu/deconfusing-direct-vs-amortised-optimizationhttps://www.quantamagazine.org/memories-help-brains-recognize-new-events-worth-remembering-20230517/https://www.reddit.com/r/MachineLearning/comments/1anv7n4/p_ai_learns_pvp_in_old_school_runescape/:
{kind=link}
{kind=link}
Bibliography
https://arxiv.org/abs/2502.04327: “Value-Based Deep RL Scales Predictably ”,https://openreview.net/forum?id=yqQJGTDGXN: “Deep Reinforcement Learning Without Experience Replay, Target Networks, or Batch Updates ”,https://arxiv.org/abs/2310.03882#deepmind: “Small Batch Deep Reinforcement Learning ”,2023-gao.pdf: “Comparative Study of Model-Based and Model-Free Reinforcement Learning Control Performance in HVAC Systems ”,https://arxiv.org/abs/2306.13831: “Minigrid & Miniworld: Modular & Customizable Reinforcement Learning Environments for Goal-Oriented Tasks ”,https://arxiv.org/abs/2305.17872: “Universal Mechanical Polycomputation in Granular Matter ”,https://arxiv.org/abs/2304.12244: “WizardLM: Empowering Large Language Models to Follow Complex Instructions ”,https://arxiv.org/abs/2211.07638: “Legged Locomotion in Challenging Terrains Using Egocentric Vision ”,https://arxiv.org/abs/2210.01542#twitter: “Hyperbolic Deep Reinforcement Learning ”,https://arxiv.org/abs/2210.01241: “Is Reinforcement Learning (Not) for Natural Language Processing: Benchmarks, Baselines, and Building Blocks for Natural Language Policy Optimization ”,https://arxiv.org/abs/2209.08466: “Simplifying Model-Based RL: Learning Representations, Latent-Space Models, and Policies With One Objective (ALM) ”,https://arxiv.org/abs/2209.07550#deepmind: “Human-Level Atari 200× Faster ”,2022-liu-3.pdf: “Quantifying and Alleviating Political Bias in Language Models ”,https://www.nature.com/articles/s41586-021-04301-9#deepmind: “Magnetic Control of Tokamak Plasmas through Deep Reinforcement Learning ”,https://proceedings.mlr.press/v162/lyle22a/lyle22a.pdf: “Learning Dynamics and Generalization in Deep Reinforcement Learning ”,https://proceedings.mlr.press/v139/vicol21a.html: “PES: Unbiased Gradient Estimation in Unrolled Computation Graphs With Persistent Evolution Strategies ”,https://arxiv.org/abs/2104.06272#deepmind: “Podracer Architectures for Scalable Reinforcement Learning ”,https://arxiv.org/abs/2103.01955: “The Surprising Effectiveness of PPO in Cooperative, Multi-Agent Games ”,https://arxiv.org/abs/2004.13649: “Image Augmentation Is All You Need: Regularizing Deep Reinforcement Learning from Pixels ”,https://openreview.net/forum?id=SyxrxR4KPS#deepmind: “Deep Neuroethology of a Virtual Rodent ”,https://arxiv.org/abs/2003.01629: “Can Increasing Input Dimensionality Improve Deep Reinforcement Learning? ”,https://arxiv.org/abs/1910.06591#deepmind: “SEED RL: Scalable and Efficient Deep-RL With Accelerated Central Inference ”,https://arxiv.org/abs/1910.01055#google: “QUARL: Quantized Reinforcement Learning (ActorQ) ”,https://karpathy.github.io/2019/04/25/recipe/: “A Recipe for Training Neural Networks ”,https://arxiv.org/abs/1901.03559#deepmind: “DRC: An Investigation of Model-Free Planning ”,https://arxiv.org/abs/1810.03779#google: “Reinforcement Learning for Improving Agent Design ”,https://openreview.net/forum?id=r1lyTjAqYX#deepmind: “R2D2: Recurrent Experience Replay in Distributed Reinforcement Learning ”,https://arxiv.org/abs/1806.04498: “The Unusual Effectiveness of Averaging in GAN Training ”,https://arxiv.org/abs/1802.01561#deepmind: “IMPALA: Scalable Distributed Deep-RL With Importance Weighted Actor-Learner Architectures ”,https://arxiv.org/abs/1712.06567#uber: “Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning ”,https://arxiv.org/abs/1710.02298#deepmind: “Rainbow: Combining Improvements in Deep Reinforcement Learning ”,https://www.sciencedirect.com/science/article/pii/S0896627317303653: “The Persistence and Transience of Memory ”,https://arxiv.org/abs/1612.00563: “Self-Critical Sequence Training for Image Captioning ”,2004-cook.pdf: “It Takes Two Neurons To Ride a Bicycle ”,2002-beyer.pdf: “Evolution Strategies: A Comprehensive Introduction ”,2001-taylor.pdf#page=6: “Recent Developments in the Evolution of Morphologies and Controllers for Physically Simulated Creatures § A Re-Implementation of Sims’ Work Using the MathEngine Physics Engine ”,